

今天早上我在博文里面更新了Spark 1.4.0正式发布,由于时间比较匆忙(要上班啊),所以在那篇文章里面只是简单地介绍了一下Spark 1.4.0,本文详细将详细地介绍Spark 1.4.0特性。如果你想尽早了解Spark等相关大数据消息,请关注本博客,或者本博客微信公共帐号iteblog_hadoop。
Apache Spark 1.4.0版本于美国时间2015年06月11日正式发布,本次发布引入SparkR(一个R语言包,主要是面向数据数据科学家)。Spark DataFrame API也带来看许多新的特性。Spark 1.2.0开始引入的ML pipelines API已经从alpha升成正式版了。Spark的Python API现在支持Python 3。最后Spark Streaming和Core中加入了可视化监控页面,可以生产环境下帮助大家调试。下面来详细地介绍这些新特性。
正式引入SparkR
Spark 1.4正式引入了SparkR(可以参见本博客的《Spark官方正式宣布支持SparkR(R on Spark)》介绍),它是一个R API,SparkR是基于Spark的DataFrame抽象。用户可以通过local R data frames或者来自Spark各种外部数据源(比如Hie表)来创建SparkR DataFrame,SparkR DataFrame支持所有Spark DataFrame所支持的操作,包括聚合、过滤、分组、汇总统计以及其他的分析函数。同时它也支持混入SQL查询,而且支持将查询结果保存成DataFrame或者从DataFrame中获取数据。因为SparkR使用的是Spark的并行计算引擎,所以它的操作将可以使用多个Core和机器,而且可以在集群中分析大规模的数据,来看下下面的例子:
people <- read.df(sqlContext, "./examples/src/main/resources/people.json", "json") head(people) ## age name ##1 NA Michael ##2 30 Andy ##3 19 Justin # SparkR automatically infers the schema from the JSON file printSchema(people) # root # |-- age: integer (nullable = true) # |-- name: string (nullable = true)
关于SparkR的编程指南,可以看这里《SparkR(R on Spark)编程指南》。
窗口函数和DataFrame的其他提升
这个版本的Spark SQL和Spark的DataFrame库引入了窗口函数,窗口函数是流行的数据分析函数,它运行用户统计窗口范围内的数据。
val w = Window.partitionBy("name").orderBy("id")
df.select(
sum("price").over(w.rangeBetween(Long.MinValue, 2)),
avg("price").over(w.rowsBetween(0, 4))
)
除此之外,社区为DataFrame带来了大量的提升,包括支持丰富的统计和数学函数(看这里《Spark1.4中DataFrame功能加强,新增科学和数学函数》)。
可视化和监控工具
生成环境下的Spark程序一般都很复杂,而且包含了很多的stages,Spark 1.4.0加入了可视化和监控工具,使得我们在spark作业运行的时候理解Spark的运行,这些都是非常棒的功能!
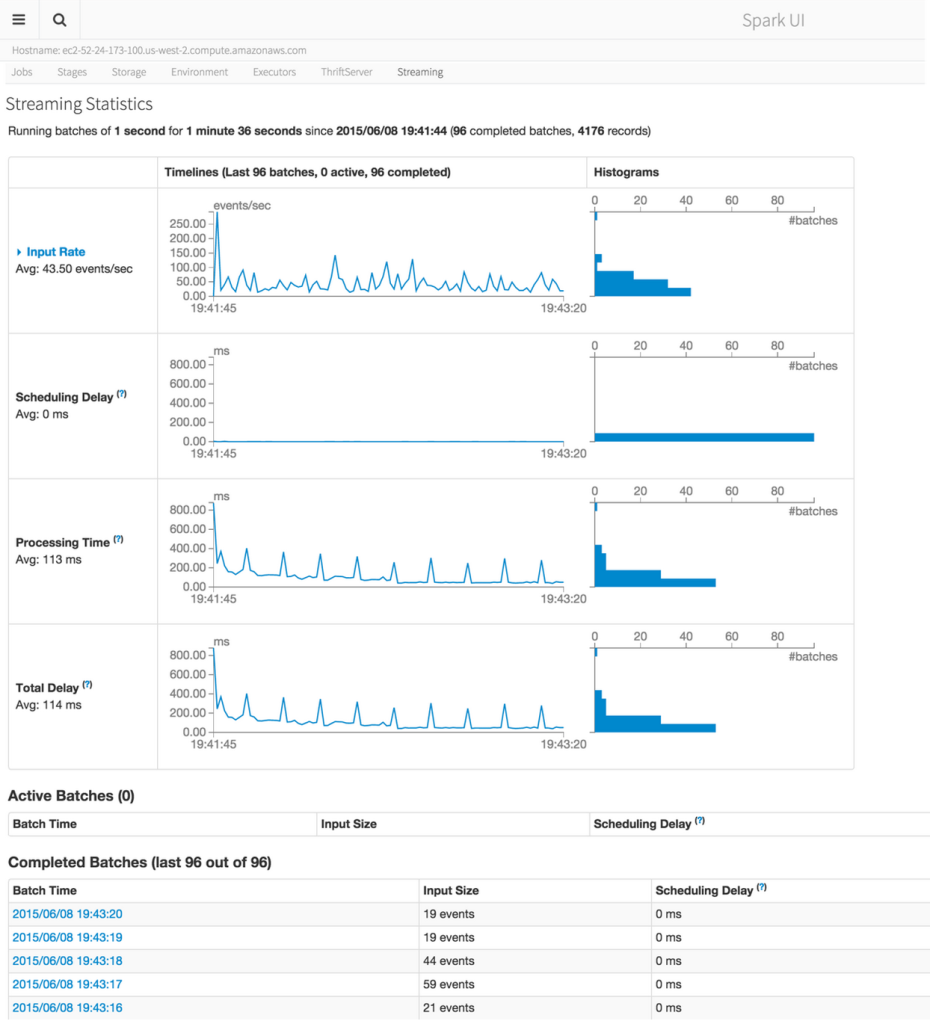
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
此外,该版本的Spark支持REST API来获取各种信息(jobs / stages / tasks / storage info),可以参见本博客的《Spark 1.4中REST API介绍》,基于这个功能,我们可以很容易的创建自己的监控工具。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Spark 1.4.0新特性详解】(https://www.iteblog.com/archives/1391.html)







大神,你好,请教下Spark任务本地化的问题。
我在一个15台机器的Hadoop2.3-cdh5.0.0的集群中,搭建了Spark1.4.0 standalone集群,每台DataNode上都起了一个Worker,然后使用spark-sql与Hive整合,查询Hive表,但无论如何,Spark所有的任务Locality Level都是ANY,spark-sql本身使用的Executor都是DataNode,为什么连一个NODE_LOCAL的任务都没有呢,能否赐教一下这其中的原理。
谢谢了!