最近有个项目需要用到手机归属地信息,所有网上找到了一些免费的API。但是因为是免费的,所有很多都有限制,比如每天只能查询多少次等。本站提供的API地址: /api/mobile.php?mobile=13188888888参数:mobile ->手机号码(7位到11位)返回格式:JSON实例结果:{ ...... w397090770 9年前 (2016-08-02) 8130℃ 4评论16喜欢
MapReduce作业可以细分为map task和reduce task,而MRAppMaster又将map task和reduce task分为四种状态: 1、pending:刚启动但尚未向resourcemanager发送资源请求; 2、scheduled:已经向resourceManager发送资源请求,但尚未分配到资源; 3、assigned:已...... w397090770 9年前 (2016-08-01) 3539℃ 0评论4喜欢
本文讲解的Hive和HBase整合意思是使用Hive读取Hbase中的数据。我们可以使用HQL语句在HBase表上进行查询、插入操作;甚至是进行Join和Union等复杂查询。此功能是从Hive 0.6.0开始引入的,详情可以参见HIVE-705。Hive与HBase整合的实现是利用两者本身对外的API接口互相进...... w397090770 9年前 (2016-07-31) 17577℃ 0评论42喜欢
《Apache Spark 2.0重大功能介绍》:/archives/1721 《Apache Spark作为编译器:深入介绍新的Tungsten执行引擎》:/archives/1679 《Spark 2.0技术预览:更容易、更快速、更智能》:/archives/1668 Apache Spark 2.0.0于2016-07-27正式发布。它是2.x版本...... w397090770 9年前 (2016-07-27) 7698℃ 4评论7喜欢
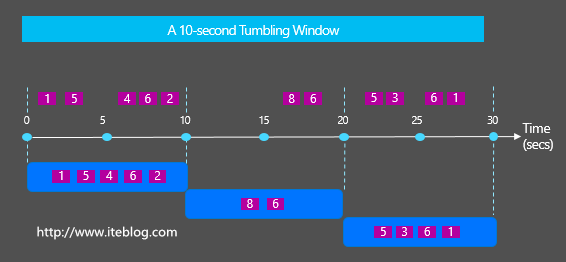
在流系统中通常会经常使用到Windows来统计一定范围的数据,比如按照固定时间、按个数等统计。一般会存在两种类型的Windows:Tumbling Windows vs Sliding Windows,它们很容易被初学者混淆,那么Tumbling Windows vs Sliding Windows之间到底有啥区别与联系呢?这就是本...... w397090770 9年前 (2016-07-26) 3583℃ 0评论4喜欢
在使用Spark streaming消费kafka数据时,程序异常中断的情况下发现会有数据丢失的风险,本文简单介绍如何解决这些问题。 在问题开始之前先解释下流处理中的几种可靠性语义: 1、At most once - 每条数据最多被处理一次(0次或1次),这种语义下会出现数据丢失的...... w397090770 9年前 (2016-07-26) 10994℃ 3评论17喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学...... w397090770 9年前 (2016-07-25) 216406℃ 0评论844喜欢
Apache Kafka在LinkedIn和其他公司中是作为各种数据管道和异步消息的后端。Netflix和Microsoft公司作为Kafka的重量级使用者(Four Comma Club,每天万亿级别的消息量),他们在Kafka Summit的分享也让人受益良多。 虽然Kafka有着极其稳定的架构,但是在每天万亿级别...... w397090770 9年前 (2016-07-20) 5393℃ 1评论6喜欢
本文根据2016年4月北京Apache Kylin Meetup上的分享讲稿整理,略有删节。美团各业务线存在大量的OLAP分析场景,需要基于Hadoop数十亿级别的数据进行分析,直接响应分析师和城市BD等数千人的交互式访问请求,对OLAP服务的扩展性、稳定性、数据精确性和性能均有很高要求。本...... w397090770 9年前 (2016-07-17) 9740℃ 0评论9喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够...... w397090770 9年前 (2016-07-14) 7692℃ 2评论4喜欢