我(不是博主,这里的我指的是Shivaram Venkataraman)很高兴地宣布即将发布的Apache Spark 1.4 release将包含SparkR,它是一个R语言包,允许数据科学家通过R shell来分析大规模数据集以及交互式地运行Jobs。 R语言是一个非常流行的统计编程语言,并且支持很多扩展以便支持数据处理和机器学习任务。然而,R中交互式地数据分析常 w397090770 10年前 (2015-06-10) 8245℃ 0评论12喜欢
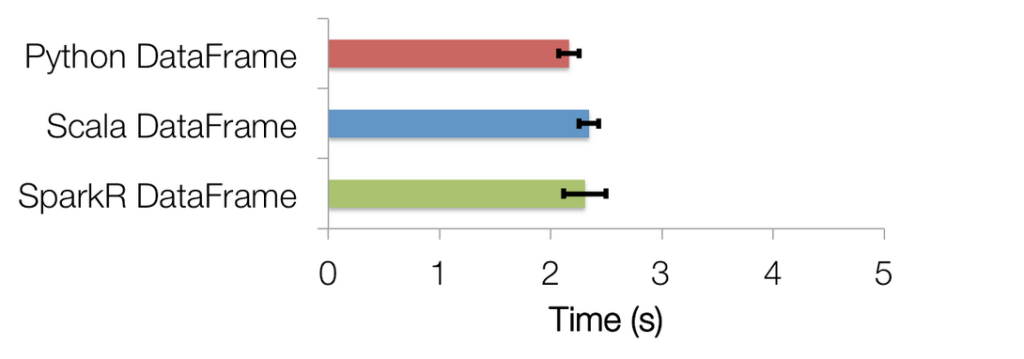
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 10年前 (2015-06-09) 36625℃ 1评论50喜欢
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个广泛应用于统计计算和统计制图的优秀编程语言,但是其交互式使用通常局限于一台机器。为了能够使用R语言分析大规模分布式的数据,UC Berkeley给我们带来了SparkR,SparkR就是用R语言编写Spark程序,它允许数据科学家分析 w397090770 10年前 (2015-04-14) 12975℃ 0评论17喜欢