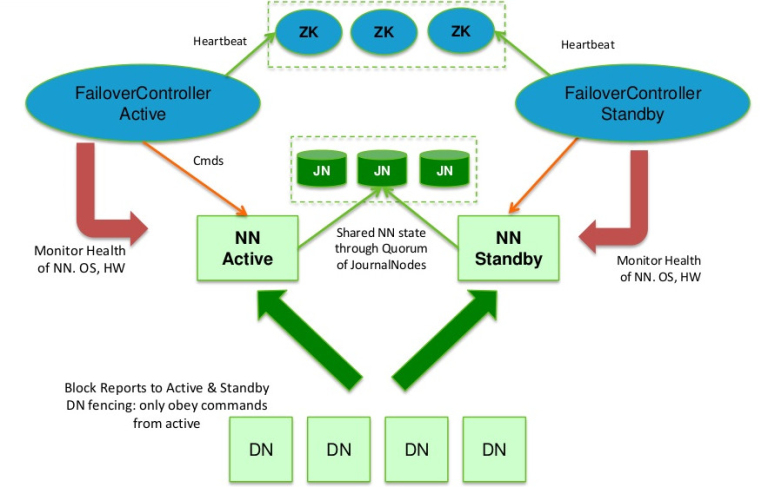
HadoopHadoop2.2.0中HDFS的高可用性实现原理 在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 11年前 (2013-11-14) 10676℃ 3评论22喜欢