理论上,在Hadoop 1.x上开发的Mapreduce程序可以在Hadoop 2.x上面运行,Hadoop2.x类库对Hadoop1.x程序的兼容性主要体现在以下几点: 二进制兼容:利用mapred API开发以及编译程序可以直接在Hadoop 2.x运行,不需要重新编译; 源码兼容:利用mapreduce API开发的程序, 需要在Hadoop 2.x上重新编译才能运行; 不兼容部分:mradmin w397090770 12年前 (2013-12-10) 6546℃ 1评论4喜欢
在《从Hadoop1.x集群升级到Hadoop2.x步骤》文章中简单地介绍了如何从Hadoop1.x集群升级到Hadoop2.x,那里面只讨论了成功升级,那么如果集群升级失败了,我们该如何从失败中回滚呢?这正是本文所有讨论的。本文将以hadoop-0.20.2-cdh3u4升级到Hadoop-2.2.0升级失败后,如何回滚。 1、如果你将Hadoop1.x升级到Hadoop2.x的过程中失败了,当你 w397090770 12年前 (2013-12-05) 5943℃ 1评论7喜欢
2013年10月15号,Hadoop已经升级到2.2.0稳定版了,同时带来了很多新的特性,本人所在的公司经过一个月时间对Hadoop2.2.0的测试,在确保对业务没有影响的前提下将Hadoop集群顺利的升级到Hadoop2.2.0版本,本文主要介绍如何从Hadoop1.x(本博客用到的是hadoop-0.20.2-cdh3u4)版本的集群顺利地升级到Hadoop2.2.0。友情提示:请在读下文之间认真 w397090770 12年前 (2013-12-02) 12646℃ 2评论8喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书籍分 w397090770 12年前 (2013-12-02) 88349℃ 59评论298喜欢
由于本文比较长,考虑到篇幅问题,所以将本文拆分为二,请阅读本文之前先阅读本文的第一部分《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》。为你带来的不变,敬请谅解。 与MultipleOutputFormat类不一样的是,MultipleOutputs可以为不同的输出产生不同类型,到这里所说的MultipleOutputs类还是旧版本的功能,后 w397090770 12年前 (2013-11-27) 21673℃ 0评论17喜欢
直到目前,我们看到的所有Mapreduce作业都输出一组文件。但是,在一些场合下,经常要求我们将输出多组文件或者把一个数据集分为多个数据集更为方便;比如将一个log里面属于不同业务线的日志分开来输出,并交给相关的业务线。 用过旧API的人应该知道,旧API中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat和org.apache.hadoop.mapr w397090770 12年前 (2013-11-26) 15278℃ 1评论10喜欢
索引是标准的数据库技术,hive 0.7版本之后支持索引。Hive提供有限的索引功能,这不像传统的关系型数据库那样有“键(key)”的概念,用户可以在某些列上创建索引来加速某些操作,给一个表创建的索引数据被保存在另外的表中。 Hive的索引功能现在还相对较晚,提供的选项还较少。但是,索引被设计为可使用内置的可插拔的java w397090770 12年前 (2013-11-15) 23375℃ 3评论16喜欢
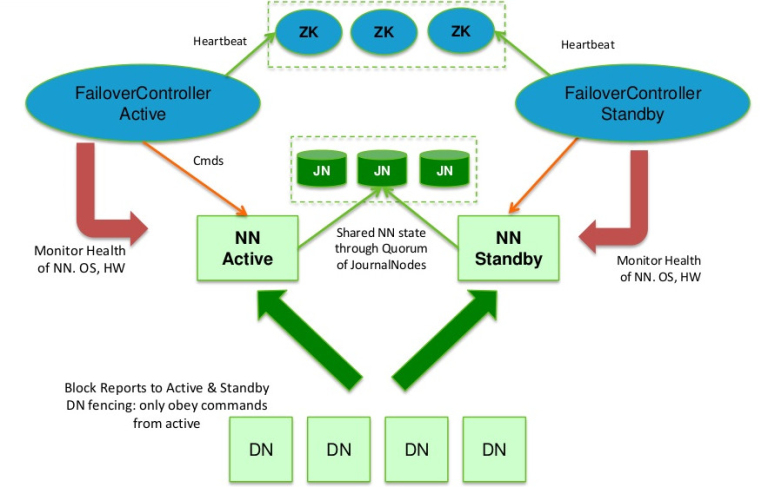
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 12年前 (2013-11-14) 10753℃ 3评论22喜欢