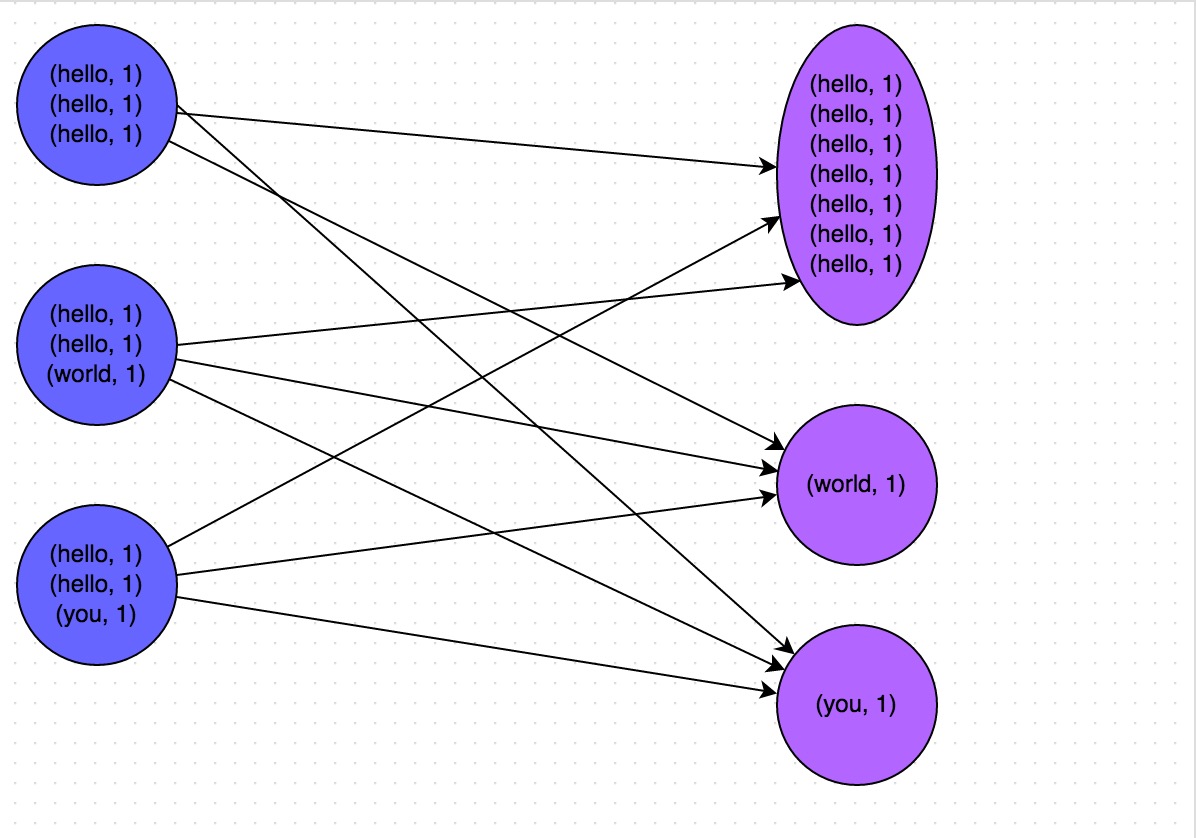
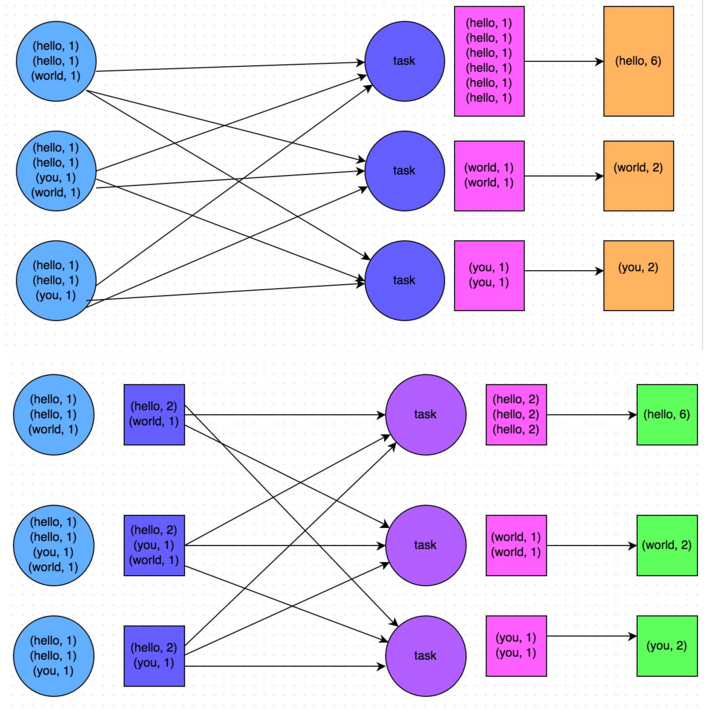
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》shuffle调优调优概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对sh w397090770 9年前 (2016-05-15) 22672℃ 2评论52喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》前言 继《Spark性能优化:开发调优篇》和《Spark性能优化:资源调优篇》讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为《Spark性能优化指南》的高级篇,将深入分析 w397090770 9年前 (2016-05-14) 15810℃ 0评论30喜欢
将于2016年6月5日星期天下午1:30在杭州市西湖区教工路88号立元大厦3楼沃创空间沃创咖啡进行,本次场地由挖财公司提供。分享主题1. 陈超, 七牛:《Spark 2.0介绍》(13:30 ~ 14:10)2. 雷宗雄, 花名念钧:《spark mllib大数据实践和优化》(14:10 ~ 14:50)3. 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》(15:10 ~ 15:50)4 w397090770 9年前 (2016-05-13) 2124℃ 0评论3喜欢
在过去的几个月时间里,我们一直忙于我们所爱的大数据开源软件的下一个主要版本开发工作:Apache Spark 2.0。Spark 1.0已经出现了2年时间,在此期间,我们听到了赞美以及投诉。Spark 2.0的开发基于我们过去两年学到的:用户所喜爱的我们加倍投入;用户抱怨的我们努力提高。本文将总结Spark 2.0的三大主题:更容易、更快速、更智 w397090770 9年前 (2016-05-12) 8884℃ 2评论26喜欢
昨天我提到了如何在《Flink Streaming中实现多路文件输出(MultipleTextOutputFormat)》,里面我们实现了一个MultipleTextOutputFormatSinkFunction类,其中封装了mutable.Map[String, TextOutputFormat[String]],然后根据key的不一样选择不同的TextOutputFormat从而实现了文件的多路输出。本文将介绍如何在Flink batch模式下实现文件的多路输出,这种模式下比较简单 w397090770 9年前 (2016-05-11) 4176℃ 3评论6喜欢
有时候我们需要根据记录的类别分别写到不同的文件中去,正如本博客的 《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(二)》以及《Spark多文件输出(MultipleOutputFormat)》等文章提到的类似。那么如何在Flink Streaming实现类似于《Spark多文件输出(MultipleOutputFormat)》文 w397090770 9年前 (2016-05-10) 8369℃ 4评论7喜欢
如果我们需要通过编程的方式来获取到Kafka中某个Topic的所有分区、副本、每个分区的Leader(所在机器及其端口等信息),所有分区副本所在机器的信息和ISR机器的信息等(特别是在使用Kafka的Simple API来编写SimpleConsumer的情况)。这一切可以通过发送TopicMetadataRequest请求到Kafka Server中获取。代码片段如下所示:[code lang="scala"]de w397090770 9年前 (2016-05-09) 8393℃ 0评论4喜欢
函数组合让我们来创建两个函数[code lang="scala"]scala> def f(s: String) = "f(" + s + ")"f: (String)java.lang.Stringscala> def g(s: String) = "g(" + s + ")"g: (String)java.lang.String[/code]compose方法compose组合其他函数形成一个新的函数f(g(x))[code lang="scala"]scala> val fComposeG = f _ compose g _fComposeG: (String) => j w397090770 9年前 (2016-05-08) 40990℃ 0评论7喜欢
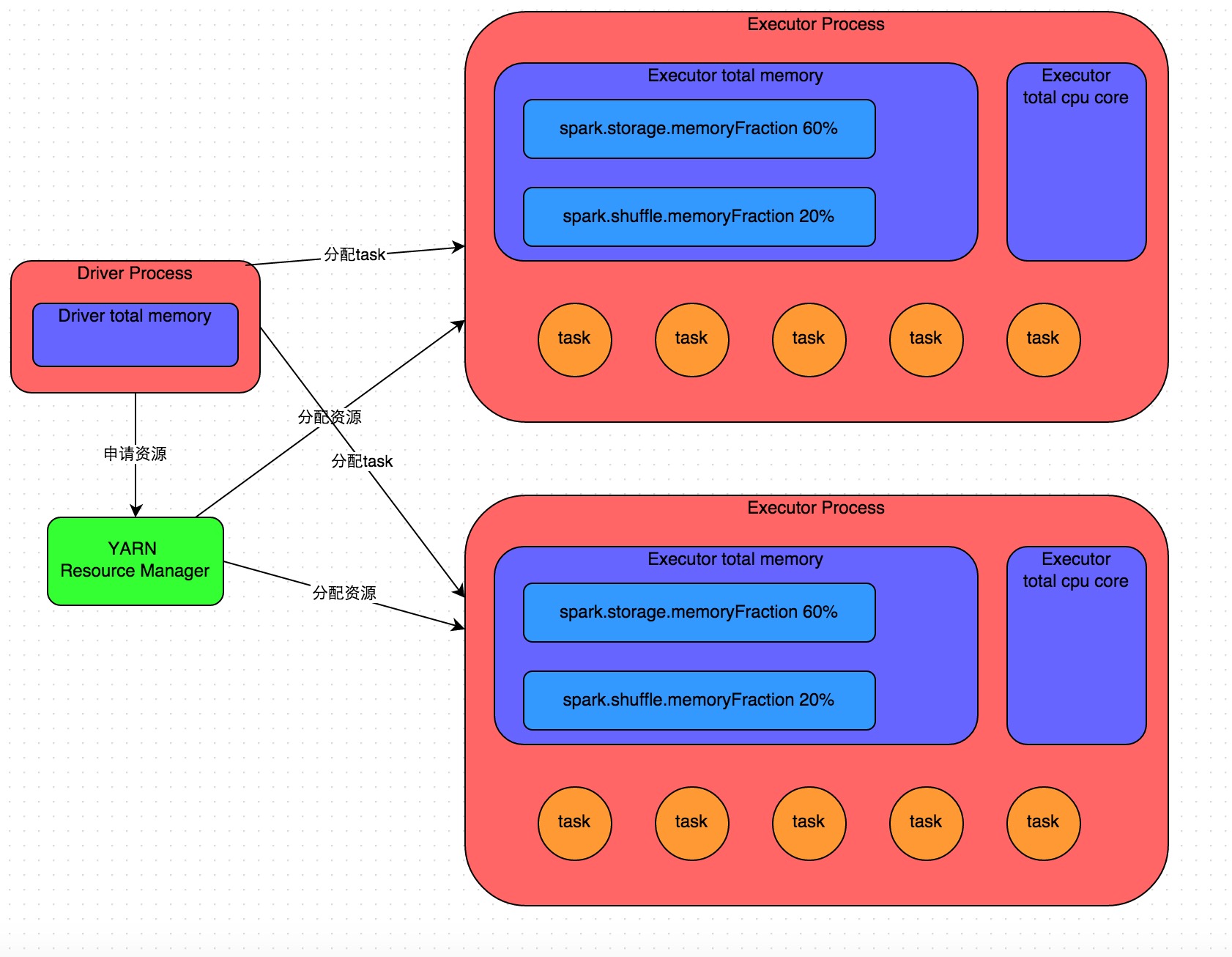
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参 w397090770 9年前 (2016-05-04) 31031℃ 8评论38喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16941℃ 3评论45喜欢