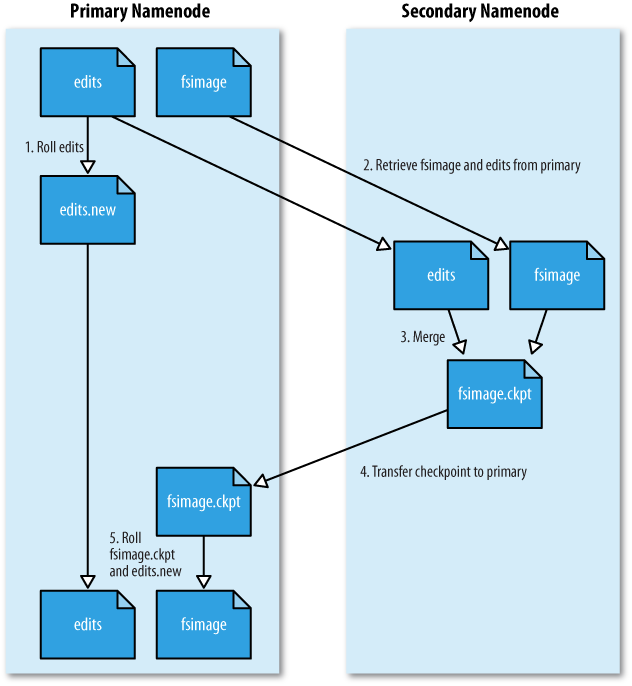
在《Hadoop文件系统元数据fsimage和编辑日志edits》文章中谈到了fsimage和edits的概念、作用等相关知识,正如前面说到,在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大;虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时候,NameNode先将fsimage里面的所有内容映像到 w397090770 11年前 (2014-03-10) 9861℃ 2评论18喜欢
在《Hadoop NameNode元数据相关文件目录解析》文章中提到NameNode的$dfs.namenode.name.dir/current/文件夹的几个文件:[code lang="JAVA"]current/|-- VERSION|-- edits_*|-- fsimage_0000000000008547077|-- fsimage_0000000000008547077.md5`-- seen_txid[/code] 其中存在大量的以edits开头的文件和少量的以fsimage开头的文件。那么这两种文件到底是什么,有什么用 w397090770 11年前 (2014-03-06) 20628℃ 1评论45喜欢
下面所有的内容是针对Hadoop 2.x版本进行说明的,Hadoop 1.x和这里有点不一样。 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:[code lang="JAVA"][wyp@wyp hadoop-2.2.0]$ $HADOOP_HOME/bin/hdfs namenode -format[/code] 格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构[code lang="JAVA"]c w397090770 11年前 (2014-03-04) 13433℃ 1评论17喜欢
Snappy是用C++开发的压缩和解压缩开发包,旨在提供高速压缩速度和合理的压缩率。Snappy比zlib更快,但文件相对要大20%到100%。在64位模式的Core i7处理器上,可达每秒250~500兆的压缩速度。 Snappy的前身是Zippy。虽然只是一个数据压缩库,它却被Google用于许多内部项目程,其中就包括BigTable,MapReduce和RPC。Google宣称它在这个库本 w397090770 11年前 (2014-03-03) 13686℃ 1评论2喜欢
分布式计算开源框架Hadoop近日发布了今年的第一个版本Hadoop-2.3.0,新版本不仅增强了核心平台的大量功能,同时还修复了大量bug。新版本对HDFS做了两个非常重要的增强:(1)、支持异构的存储层次;(2)、通过数据节点为存储在HDFS中的数据提供了内存缓存功能。 借助于HDFS对异构存储层次的支持,我们将能够在同一个Hado w397090770 11年前 (2014-03-02) 4218℃ 0评论1喜欢