《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 第三次北京Spark Meetup活动 w397090770 11年前 (2014-11-06) 15891℃ 134评论11喜欢
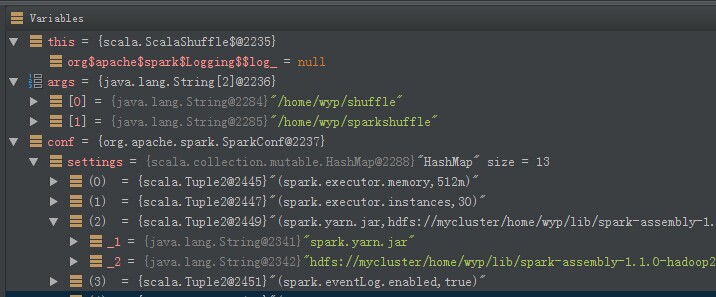
我们在编写Spark Application或者是阅读源码的时候,我们很想知道代码的运行情况,比如参数设置的是否正确等等。用Logging方式来调试是一个可以选择的方式,但是,logging方式调试代码有很多的局限和不便。今天我就来介绍如何通过IDE来远程调试Spark的Application或者是Spark的源码。本文以调试Spark Application为例进行说明,本文用到的I w397090770 11年前 (2014-11-05) 24105℃ 16评论21喜欢
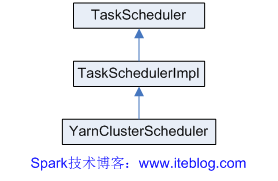
《Spark on YARN集群模式作业运行全过程分析》《Spark on YARN客户端模式作业运行全过程分析》《Spark:Yarn-cluster和Yarn-client区别与联系》《Spark和Hadoop作业之间的区别》《Spark Standalone模式作业运行全过程分析》(未发布) 在前篇文章中我介绍了Spark on YARN集群模式(yarn-cluster)作业从提交到运行整个过程的情况(详情见《Spar w397090770 11年前 (2014-11-04) 19654℃ 5评论12喜欢
《Spark on YARN集群模式作业运行全过程分析》《Spark on YARN客户端模式作业运行全过程分析》《Spark:Yarn-cluster和Yarn-client区别与联系》《Spark和Hadoop作业之间的区别》《Spark Standalone模式作业运行全过程分析》(未发布) 下面是分析Spark on YARN的Cluster模式,从用户提交作业到作业运行结束整个运行期间的过程分析。客户 w397090770 11年前 (2014-11-03) 25197℃ 3评论38喜欢
本文转载自:http://shiyanjun.cn/archives/744.html 该论文来自Berkeley实验室,英文标题为:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing。摘要 本文提出了分布式内存抽象的概念——弹性分布式数据集(RDD,Resilient Distributed Datasets),它具备像MapReduce等数据流模型的容错特性,并且允许开发人员 w397090770 11年前 (2014-10-30) 13734℃ 0评论7喜欢
《Spark源码分析:多种部署方式之间的区别与联系(1)》《Spark源码分析:多种部署方式之间的区别与联系(2)》 在《Spark源码分析:多种部署方式之间的区别与联系(1)》我们谈到了SparkContext的初始化过程会做好几件事情(这里就不再列出,可以去《Spark源码分析:多种部署方式之间的区别与联系(1)》查看),其中做了一件重要 w397090770 11年前 (2014-10-28) 7765℃ 6评论8喜欢
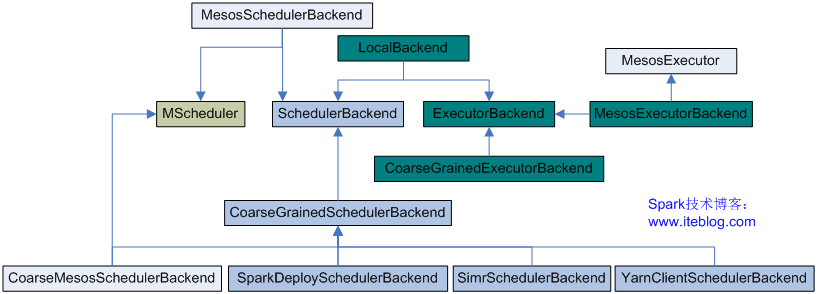
《Spark源码分析:多种部署方式之间的区别与联系(1)》 《Spark源码分析:多种部署方式之间的区别与联系(2)》 从官方的文档我们可以知道,Spark的部署方式有很多种:local、Standalone、Mesos、YARN.....不同部署方式的后台处理进程是不一样的,但是如果我们从代码的角度来看,其实流程都差不多。 从代码中,我们 w397090770 11年前 (2014-10-24) 7775℃ 2评论14喜欢
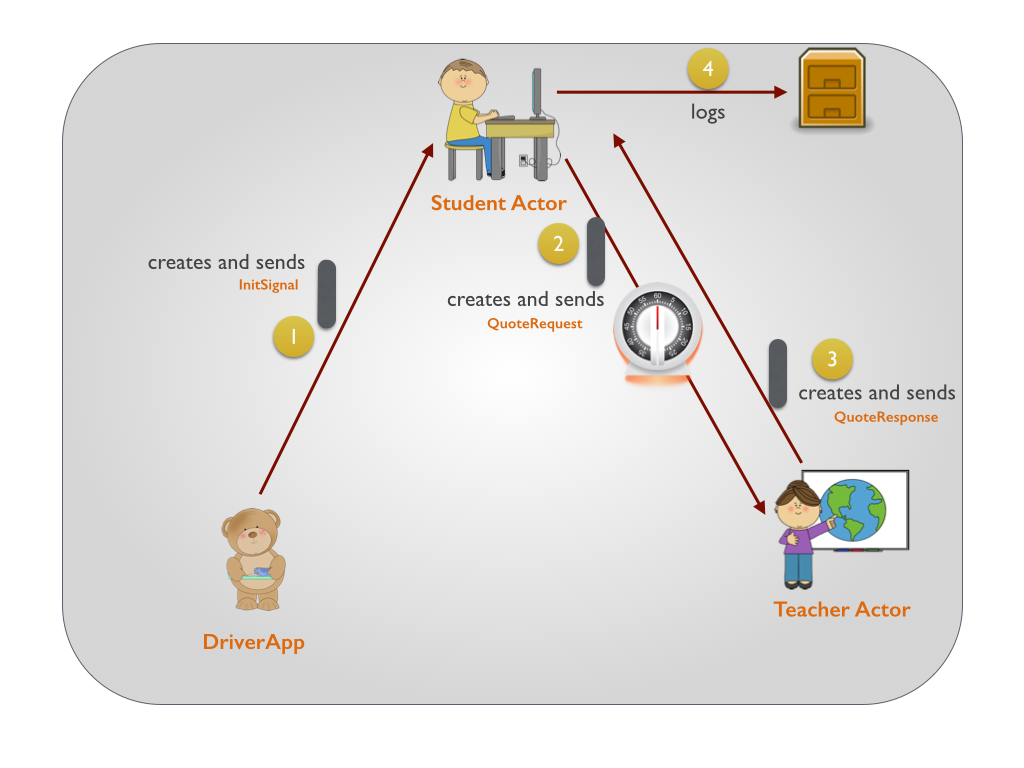
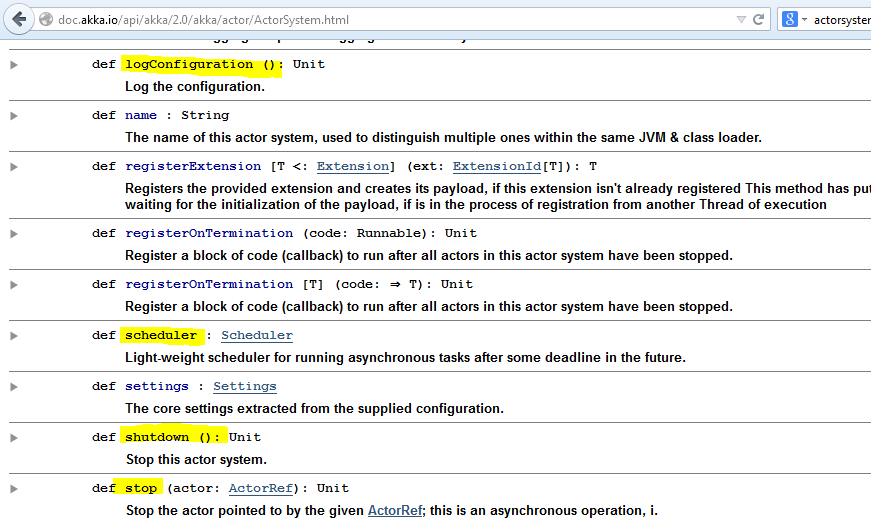
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 11年前 (2014-10-22) 19345℃ 3评论14喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 11年前 (2014-10-21) 15860℃ 4评论12喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 11年前 (2014-10-19) 7404℃ 6评论10喜欢