目前市面上流行的三大开源数据湖方案分别为:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商业化上取得巨大成功,所以由其背后商业公司 Databricks 推出的 Delta 也显得格外亮眼。Apache Hudi 是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete 以及 compaction 等功能可以说是精准命中 w397090770 5年前 (2020-03-05) 4072℃ 0评论2喜欢
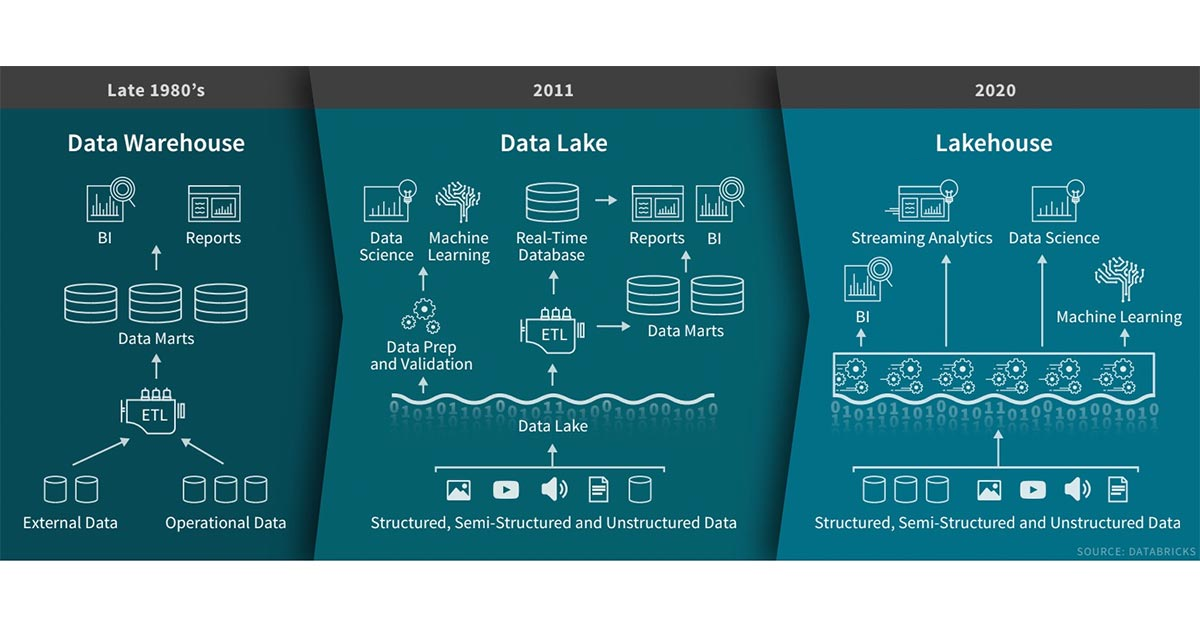
引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 5年前 (2020-02-03) 3047℃ 0评论6喜欢
本博客盘点了过去两年晋升为 Apache TLP(Apache Top-Level Project) 的大数据相关项目,具体参见《盘点2017年晋升为Apache TLP的大数据相关项目》、《盘点2018年晋升为Apache TLP的大数据相关项目》,继承这个惯例,本文将给大家盘点2019年晋升为 Apache TLP 的大数据相关项目,由于今年晋升成 TLP 的大数据项目很少,只有三个,而且其中两个好 w397090770 6年前 (2019-12-30) 2369℃ 0评论7喜欢
Delta Lake 是数砖公司在2017年10月推出来的一个项目,并于2019年4月24日在美国旧金山召开的 Spark+AI Summit 2019 会上开源的一个存储层。它是 Databricks Runtime 重要组成部分。为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构 w397090770 6年前 (2019-12-24) 4469℃ 0评论8喜欢
Apache Hudi 对个人和组织何时有用如果你希望将数据快速提取到HDFS或云存储中,Hudi可以提供帮助。另外,如果你的ETL /hive/spark作业很慢或占用大量资源,那么Hudi可以通过提供一种增量式读取和写入数据的方法来提供帮助。作为一个组织,Hudi可以帮助你构建高效的数据湖,解决一些最复杂的底层存储管理问题,同时将数据更快 w397090770 6年前 (2019-12-23) 2070℃ 0评论2喜欢
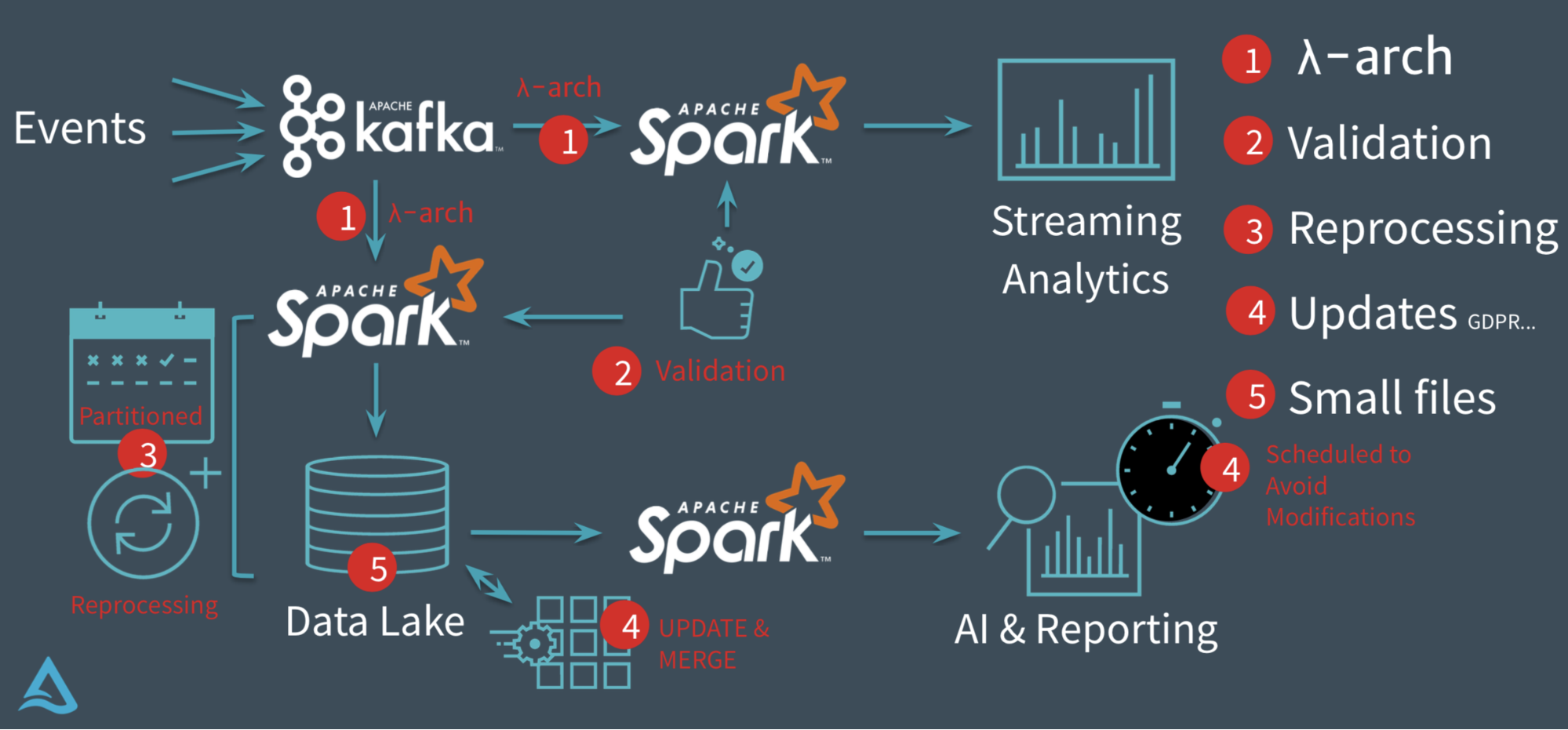
随着 Apache Parquet 和 Apache ORC 等存储格式以及 Presto 和 Apache Impala 等查询引擎的发展,Hadoop 生态系统有可能成为一个面向几分钟延迟工作负载的通用统一服务层。但是,为了实现这一点,需要在 Hadoop 分布式文件系统(HDFS)中实现高效、低延迟的数据摄取和数据准备。为了解决这个问题,Uber 构建了Hudi(被称为“hoodie”),这是一个 w397090770 6年前 (2019-11-21) 5254℃ 2评论9喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 6年前 (2019-06-06) 3394℃ 0评论8喜欢
快速管理和访问 PB 级数据的能力对于整个数据生态系统的可伸缩增长是至关重要的。尽管如此,这种对规模和速度的综合需求并不总是自然地适合现有的批处理和流系统架构。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHudi 于 2016 年以“Hoodie”为代号开发,旨在解决 Uber 大数据生态系统 w397090770 6年前 (2019-04-20) 975℃ 0评论1喜欢