每个Java开发人员都知道字节码经由JRE(Java运行时环境)执行。但他们或许不知道JRE其实是由Java虚拟机(JVM)实现,JVM分析字节码,解释并执行它。作为开发人员,了解JVM的架构是非常重要的,因为它使我们能够编写出更高效的代码。本文中,我们将深入了解Java中的JVM架构和JVM的各个组件。
JVM
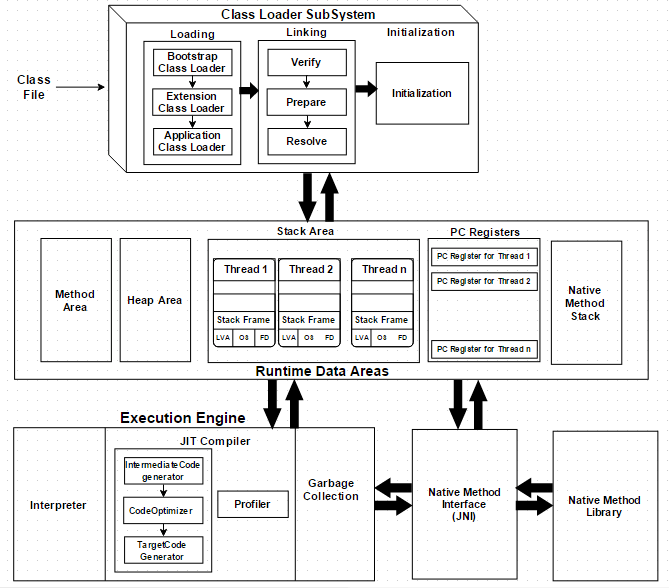
虚拟机是物理机的软件实现。Java的设计理念是WORA(Write Once Run Anywhere,一次编写随处运行)。编译器将Java文件编译为Java .class文件,然后将.class文件输入到JVM中,JVM执行类文件的加载和执行的操作。请看以下的JVM架构图:
如果想及时了解Spark、Flink、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
JVM是如何工作的
如上面架构图所示,JVM分为三个主要子系统:
1、类加载器子系统(Class Loader Subsystem)
2、运行时数据区(Runtime Data Area)
3、执行引擎(Execution Engine)
类加载器子系统
Java的动态类加载功能由类加载器子系统处理,处理过程包括加载和链接,并在类文件运行时,首次引用类时就开始实例化类文件,而不是在编译时进行。
1.1 加载
Boot Strap类加载器,Extension类加载器和Application(类加载器是实现类加载过程的三个类加载器。
(1) Boot Strap类加载器:负责从引导类路径加载类,除了rt.jar,它具有最高优先级;
(2) Extension 类加载器:负责加载ext文件夹(jre \ lib)中的类;
(3) Application类加载器:负责加载应用程序级类路径,环境变量中指定的路径等信息。
上面的类装载器在加载类文件时遵循委托层次算法(Delegation Hierarchy Algorithm)。
1.2 链接
(1) 验证(Verify):字节码验证器将验证生成的字节码是否正确,如果验证失败,将提示验证错误;
(2) 准备(Prepare):对于所有静态变量,内存将会以默认值进行分配;
(3) 解释(Resolve):有符号存储器引用都将替换为来自方法区(Method Area)的原始引用。
1.3 初始化
这是类加载的最后阶段,所有的静态变量都将被赋予原始值,并且静态区块将被执行。
运行时数据区
运行时数据区可分为5个主要组件:
(1) 方法区(Method Area):所有的类级数据将存储在这里,包括静态变量。每个JVM只有一个方法区,它是一个共享资源;
(2) 堆区域(Heap Area):所有对象及其对应的实例变量和数组将存储在这里。每个JVM也只有一个堆区域。由于方法和堆区域共享多个线程的内存,所存储的数据不是线程安全的;
(3) 堆栈区(Stack Area):对于每个线程,将创建单独的运行时堆栈。对于每个方法调用,将在堆栈存储器中产生一个条目,称为堆栈帧。所有局部变量将在堆栈内存中创建。堆栈区域是线程安全的,因为它不共享资源。堆栈框架分为三个子元素:
a、局部变量数组(Local Variable Array):与方法相关,涉及局部变量,并在此存储相应的值
b、操作数堆栈(Operand stack):如果需要执行任何中间操作,操作数堆栈将充当运行时工作空间来执行操作
c、帧数据(Frame Data):对应于方法的所有符号存储在此处。在任何异常的情况下,捕获的区块信息将被保持在帧数据中;
(4) PC寄存器(PC Registers):每个线程都有单独的PC寄存器,用于保存当前执行指令的地址。一旦执行指令,PC寄存器将被下一条指令更新;
(5) 本地方法堆栈(Native Method stacks):本地方法堆栈保存本地方法信息。对于每个线程,将创建一个单独的本地方法堆栈。
执行引擎
分配给运行时数据区的字节码将由执行引擎执行,执行引擎读取字节码并逐个执行。
(1) 解释器:解释器更快地解释字节码,但执行缓慢。解释器的缺点是当一个方法被调用多次时,每次都需要一个新的解释;
(2) JIT编译器:JIT编译器消除了解释器的缺点。执行引擎将在转换字节码时使用解释器的帮助,但是当它发现重复的代码时,将使用JIT编译器,它编译整个字节码并将其更改为本地代码。这个本地代码将直接用于重复的方法调用,这提高了系统的性能。JIT的构成组件为:
a、中间代码生成器(Intermediate Code Generator):生成中间代码
b、代码优化器(Code Optimizer):负责优化上面生成的中间代码
c、目标代码生成器(Target Code Generator):负责生成机器代码或本地代码
d、分析器(Profiler):一个特殊组件,负责查找热点,即该方法是否被多次调用;
(3) 垃圾收集器(Garbage Collector):收集和删除未引用的对象。可以通过调用“System.gc()”触发垃圾收集,但不能保证执行。JVM的垃圾回收对象是已创建的对象。
Java本机接口(JNI):JNI将与本机方法库进行交互,并提供执行引擎所需的本机库。
本地方法库(Native Method Libraries):它是执行引擎所需的本机库的集合。
英文原文:The JVM Architecture Explained
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【JVM体系结构解释】(https://www.iteblog.com/archives/1957.html)