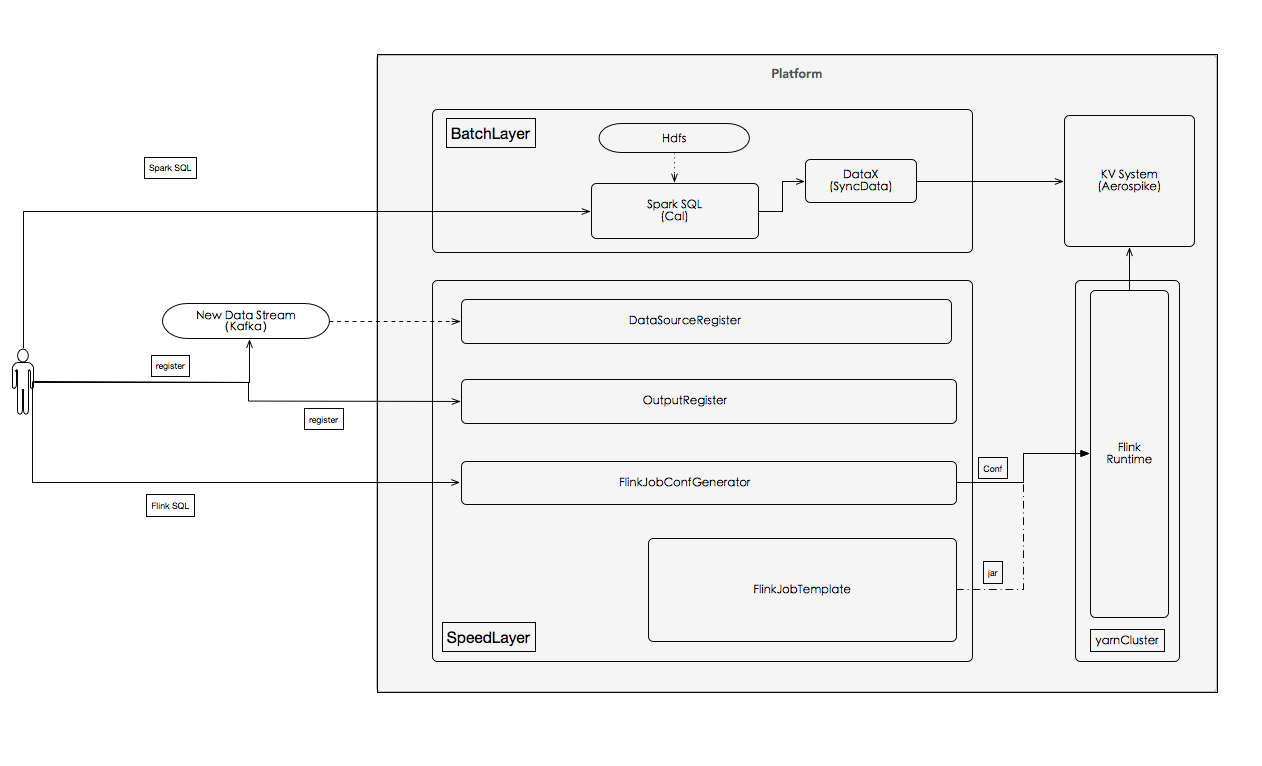
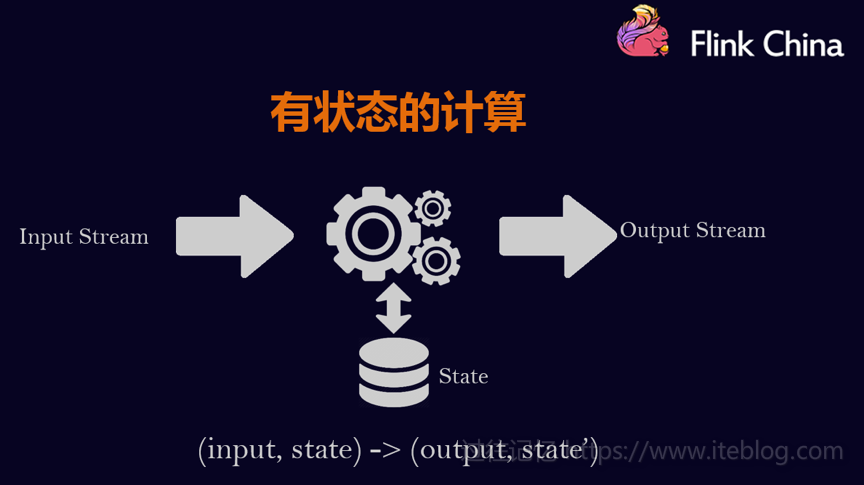
本文整理自8月11日在北京举行的 Flink Meetup 会议,分享嘉宾施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。本文由韩非(Flink China社区志愿者)整理一、有状态的流数据处理1、什么是有状态的计算计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大 w397090770 10小时前 21℃ 0评论0喜欢
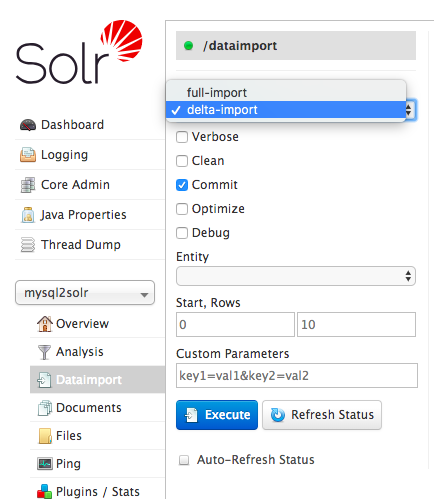
在 这篇 和 这篇 文章中我分别介绍了如何将 MySQL 的全量数据导入到 Apache Solr 中以及如何分页导入等,本篇文章将继续介绍如何将 MySQL 的增量数据导入到 Solr 中。增量导数接口为 deltaimport,对应的页面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如果我们使用 《将 MySQL 的全量 w397090770 6天前 87℃ 0评论2喜欢
本文来自于王新春在2018年7月29日 Flink China社区线下 Meetup·上海站的分享。王新春目前在唯品会负责实时平台相关内容,主要包括实时计算框架和提供实时基础数据,以及机器学习平台的工作。之前在美团点评,也是负责大数据平台工作。他已经在大数据实时处理方向积累了丰富的工作经验。。本文主要内容如下:唯品会实时 zz~~ 1周前 (08-15) 310℃ 0评论2喜欢
本文来自7月26日在上海举行的 Flink Meetup 会议,分享来自于刘康,目前在大数据平台部从事模型生命周期相关平台开发,现在主要负责基于flink开发实时模型特征计算平台。熟悉分布式计算,在模型部署及运维方面有丰富实战经验和深入的理解,对模型的算法及训练有一定的了解。本文主要内容如下:在公司实时特征开发的现 zz~~ 1周前 (08-14) 221℃ 0评论2喜欢
Flink China社区线下 Meetup·北京站会议于 2018年8月11日 在朝阳区酒仙桥北路恒通国际创新园进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动议程13:40-13:50 莫问 出品人开场发言13:50-14:30 Flink Committer星罡《Flink状态管理和恢复技术介绍》,详细请见这里14:30-15:10 滴滴 余海琳《Flink在 zz~~ 2周前 (08-14) 180℃ 0评论1喜欢
Flink China社区线下 Meetup·上海站会议于 2018年7月29日 在上海市杨浦区政学路77号INNOSPACE进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动议程14:00-14:10 大沙 出品人开场发言14:10-14:40 阿里 巴真 《阿里在Flink的优化和改进分享》14:40-15:10 唯品会 王新春 《Flink在唯品会的实践》详细 w397090770 2周前 (08-13) 189℃ 0评论4喜欢
为期两个月开发的 Apache Flink 1.6.0 于今天(2018-08-09)正式发布了。Flink 社区艰难地解决了 360 个 issues,到这里查看完整版的 changelog 。Flink 1.6.0 是 1.x.y 版本系列上的第七个版本,1.x.y 中所有使用 @Public 标注的 API 都是兼容的。此版本继续使 Flink 用户能够无缝地运行快速数据处理并轻松构建数据驱动和数据密集型应用程序。Apache Fli w397090770 2周前 (08-09) 251℃ 0评论7喜欢
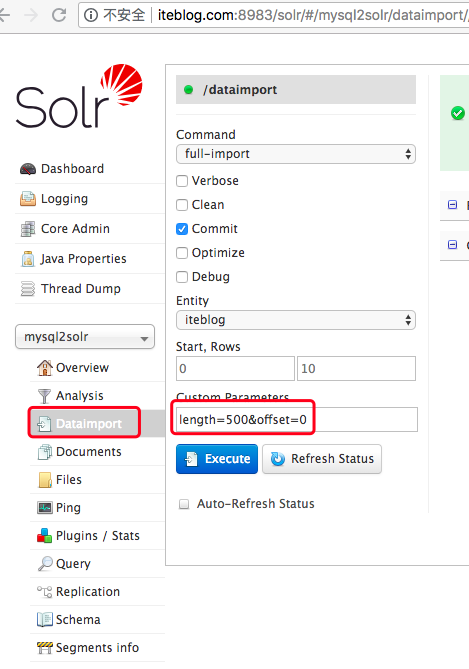
在 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章中介绍了如何将 MySQL 中的全量数据导入到 Solr 中。里面提到一个问题,那就是如果数据量很大的时候,一次性导入数据可能会影响 MySQL ,这种情况下能不能分页导入呢?答案是肯定的,本文将介绍如何通过分页的方式将 MySQL 里面的数据导入到 Solr。分页导数的方法和全量导大部 w397090770 2周前 (08-07) 120℃ 0评论1喜欢
如果你正在按照 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章介绍的步骤来将 MySQL 里面的数据导入到 Solr 中,但是在创建 Core/Collection 的时候出现了以下的异常[code lang="bash"]2018-08-02 07:56:17.527 INFO (qtp817348612-15) [ x:mysql2solr] o.a.s.m.r.SolrJmxReporter Closing reporter [org.apache.solr.metrics.reporters.SolrJmxReporter@47d9861c: rootName = null, domain = solr.cor w397090770 3周前 (08-07) 45℃ 0评论0喜欢
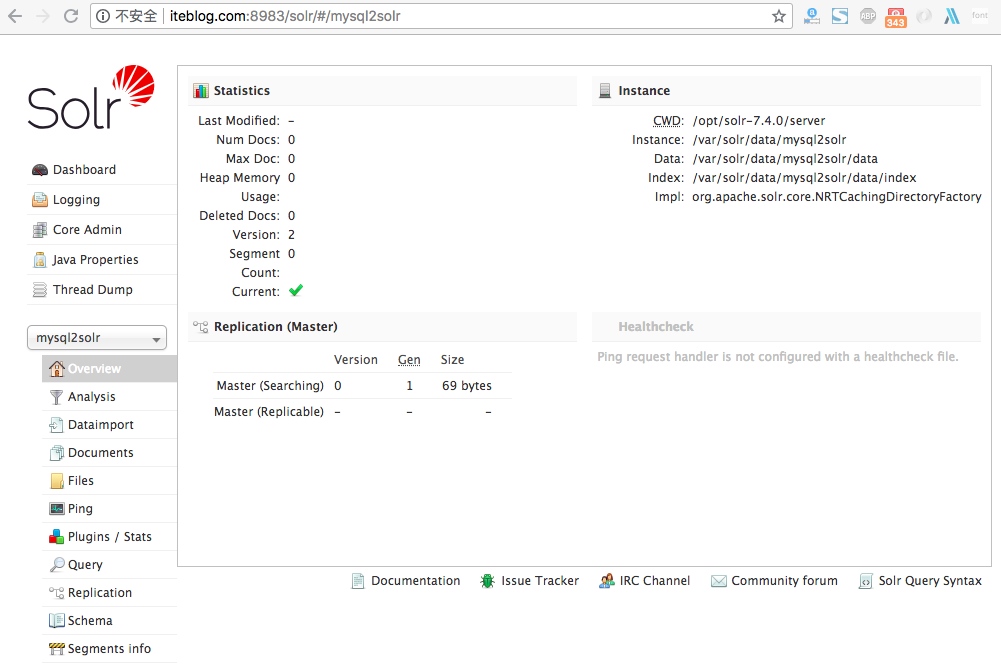
关于分页方式导入全量数据请参照《将 MySQL 的全量数据以分页的形式导入到 Apache Solr 中》。在前面几篇文章中我们介绍了如何通过 Solr 的 post 命令将各种各样的文件导入到已经创建好的 Core 或 Collection 中。但有时候我们需要的数据并不在文件里面,而是在别的系统中,比如 MySql 里面。不过高兴的是,Solr 针对这些数据也提供了 w397090770 3周前 (08-06) 107℃ 0评论1喜欢



![Spark Summit North America 201806 全部PPT下载[共147个]](https://www.iteblog.com/pic/spark/spark-summit-north-america-2018-06_iteblog.png "Spark Summit North America 201806 全部PPT下载[共147个]")


")



")