从名字就可以看出这是笛卡儿的意思,就是对给的两个RDD进行笛卡儿计算。官方文档说明:Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of elements (a, b) where a is in `this` and b is in `other`.函数原型def cart...... w397090770 11年前 (2015-03-07) 11376℃ 0评论5喜欢
使用MEMORY_ONLY储存级别对RDD进行缓存,其内部实现是调用persist()函数的。官方文档定义:Persist this RDD with the default storage level (`MEMORY_ONLY`).函数原型def cache() : this.type实例/** * User: 过往记忆 * Date: 15-03-04 * Time: ...... w397090770 11年前 (2015-03-04) 14224℃ 0评论8喜欢
该函数和aggregate类似,但操作的RDD是Pair类型的。Spark 1.1.0版本才正式引入该函数。官方文档定义:Aggregate the values of each key, using given combine functions and a neutral "zero value". This function can return a different result type, U, than the ...... w397090770 11年前 (2015-03-02) 39682℃ 2评论35喜欢
相关图标矢量字库:《Font Awesome:图标字体》、《阿里巴巴矢量图标库:Iconfont》 Iconfont.cn是由阿里巴巴UX部门推出的矢量图标管理网站,也是国内首家推广Webfont形式图标的平台。网站涵盖了1000多个常用图标并还在持续更新中(目前加上用户上传的图标近70000个...... w397090770 11年前 (2015-02-26) 30669℃ 0评论27喜欢
我们先来看看aggregate函数的官方文档定义:Aggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral "zero value". This function can return a different result type, U, than the t...... w397090770 11年前 (2015-02-12) 37501℃ 5评论23喜欢
Learning Spark这本书链接是完整版,和之前的预览版是不一样的,我不是标题党。这里提供的Learning Spark电子书格式是mobi、pdf以及epub三种格式的文件,如果你有亚马逊Kindle电子书阅读器,是可以直接阅读mobi、pdf。但如果你用电脑,也可以下载相应的PC版阅读器 。如果你...... w397090770 11年前 (2015-02-11) 51447℃ 305评论70喜欢
美国时间2015年2月09日Spark 1.2.1正式发布了,邮件如下:Hi All,I've just posted the 1.2.1 maintenance release of Apache Spark. We recommend all 1.2.0 users upgrade to this release, as this release includes stability fixes across all components of Sp...... w397090770 11年前 (2015-02-10) 3536℃ 0评论2喜欢
美国时间2015年2月4日,Hive 1.0.0正式发布了。该版本是Apache Hive九年来工作的认可,并且开发者们正在继续开发。Apache Hive 1.0.0版本本来是要命名为Hive 0.14.1的,但是社区感觉是时候以1.x.y结构来命名。 虽然被叫做1.0.0版本,但是其中的改变范围很少,主要有...... w397090770 11年前 (2015-02-06) 7164℃ 0评论3喜欢
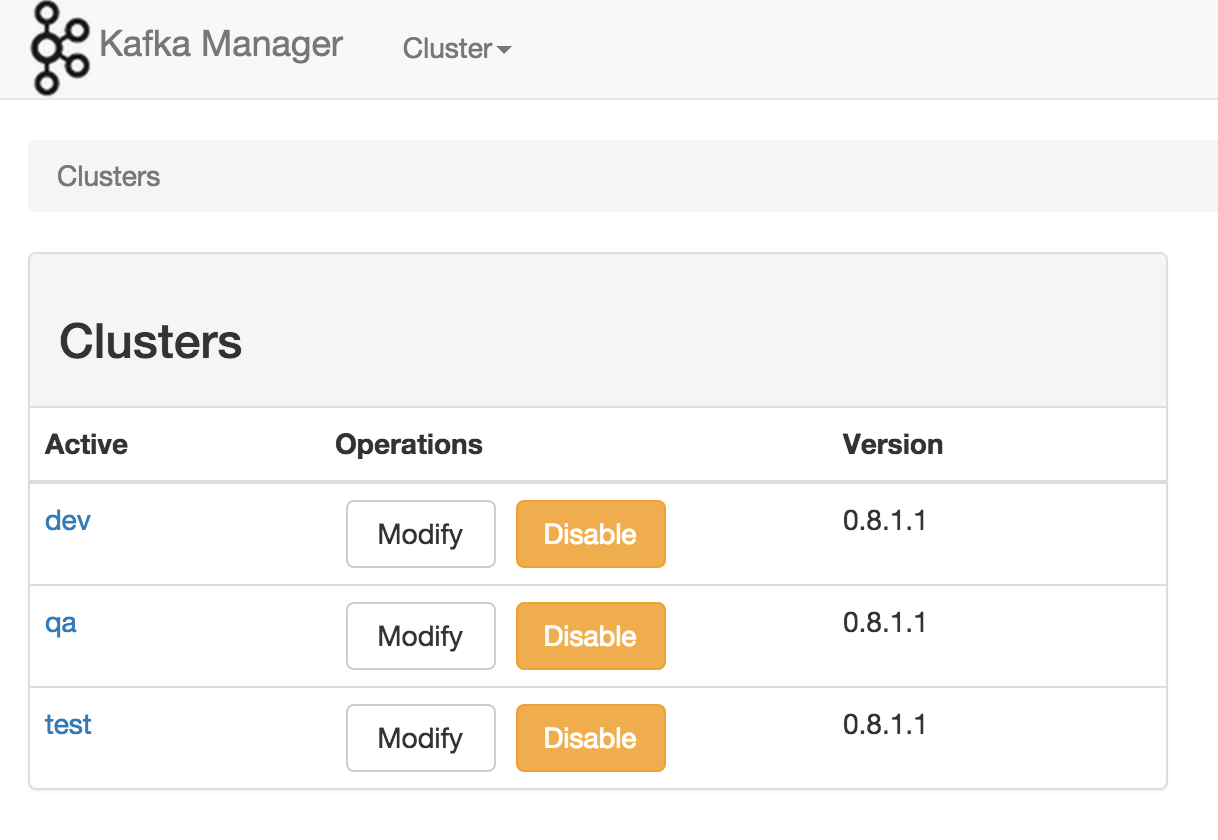
《Apache Kafka监控之Kafka Web Console》《Apache Kafka监控之KafkaOffsetMonitor》《雅虎开源的Kafka集群管理器(Kafka Manager)》Kafka在雅虎内部被很多团队使用,媒体团队用它做实时分析流水线,可以处理高达20Gbps(压缩数据)的峰值带宽。为了简化开发者和服务工程师...... w397090770 11年前 (2015-02-04) 22155℃ 0评论14喜欢
在这篇文章中,我将介绍一下Spark SQL对Json的支持,这个特性是Databricks的开发者们的努力结果,它的目的就是在Spark中使得查询和创建JSON数据变得非常地简单。随着WEB和手机应用的流行,JSON格式的数据已经是WEB Service API之间通信以及数据的长期保存的事实上的标准...... w397090770 11年前 (2015-02-04) 14453℃ 1评论16喜欢