通过使用易于理解的实例,本书将教你如何使用Spark Streaming构建实时应用程序。从安装和设置所需的环境开始,您将编写并执行第一个程序Spark Streaming。接下来将探讨Spark Streaming的架构和组件以及概述Spark公开的库/函数的。接下来,您将通过处理分布式日志文件的...... w397090770 9年前 (2017-02-12) 3154℃ 0评论6喜欢
Elasticsearch的config文件夹里面有两个配置文件:elasticsearch.yml和logging.yml。第一个是es的基本配置文件,第二个是日志配置文件,es也是使用log4j来记录日志的,所以logging.yml里的设置按普通log4j配置文件来设置就行了。下面主要讲解下elasticsearch.yml这个文...... w397090770 9年前 (2017-02-11) 1938℃ 0评论4喜欢
Spark Summit East 2017会议于2017年2月07日到09日在波士顿进行,本次会议有来自工业界的上百位Speaker;官方日程:https://spark-summit.org/east-2017/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收...... w397090770 9年前 (2017-02-11) 1574℃ 0评论1喜欢
今天,Apache Beam 0.5.0 发布了,此版本通过新的State API添加对状态管道的支持,并通过新的Timer API添加对计时器的支持。 此外,该版本还为Elasticsearch和MQ Telemetry Transport(MQTT)添加了新的IO连接器,以及常见的一些错误修复和改进。对于此版本中的所有主要...... w397090770 9年前 (2017-02-10) 1139℃ 0评论2喜欢
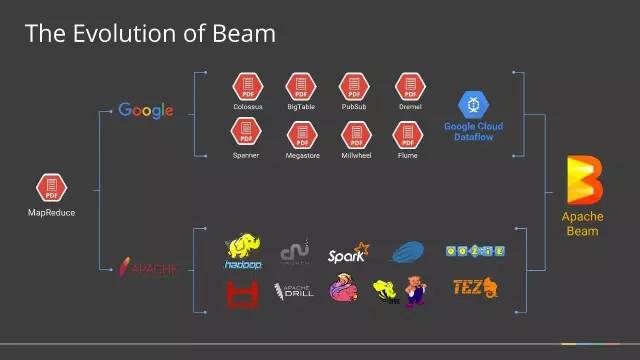
1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源。 2003年,谷歌发布了著名的大数据三篇论文,史称三驾马车:Google FS、MapReduce、BigTable。虽然谷歌没有公布这三个产品的源码,但是她这三个产品...... w397090770 9年前 (2017-02-10) 1843℃ 0评论4喜欢
Spark已经成为数据科学专业人士最有前途的大数据分析引擎。Apache Spark真正的力量和价值在于它能够以高速和准确的方式执行数据科学任务;Spark的卖点是它结合ETL,批处理分析,实时流分析,机器学习,图形处理和可视化;它允许您轻松处理非结构化的原始数据集。 本...... w397090770 9年前 (2017-02-10) 2268℃ 0评论6喜欢
为了提高 HBase 存储的利用率,很多 HBase 使用者会对 HBase 表中的数据进行压缩。目前 HBase 可以支持的压缩方式有 GZ(GZIP)、LZO、LZ4 以及 Snappy。它们之间的区别如下:GZ:用于冷数据压缩,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速...... w397090770 9年前 (2017-02-09) 2069℃ 0评论1喜欢
大家对加州大学伯克利分校的AMPLab可能不太熟悉,但是它的项目我们都有所耳闻——没错,它就是Spark和Mesos的诞生之地。AMPLab是加州大学伯克利分校一个为期五年的计算机研究计划,其初衷是为了理解机器和人如何合作处理和解决数据中的问题——使用数据去训练更加丰富的模型,...... w397090770 9年前 (2017-02-09) 1420℃ 0评论3喜欢
Introduce Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。 容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小...... zz~~ 9年前 (2017-02-08) 4612℃ 0评论7喜欢
大家期待已久的Apache Flink 1.2.0今天终于正式发布了。本版本一共解决了650个issues,详细的列表参见这里。Apache Flink 1.2.0是1.x.y系列的第三个主要版本;其API和其他1.x.y版本使用@Public标注的API是兼容的,推荐所有用户升级到此版本。更多关于Apache Flink 1.2....... w397090770 9年前 (2017-02-07) 1998℃ 6喜欢

![[电子书]Learning Real-time Processing with Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Real-time_Processing_with_Spark_Streaming-iteblog.jpg)

![Spark Summit East 2017部分PPT下载[共18个]](https://www.iteblog.com/pic/iteblog.png)

![[电子书]Apache Spark for Data Science Cookbook PDF下载](https://www.iteblog.com/pic/books/Spark_for_Data_Science_Cookbook_iteblog.jpg)


