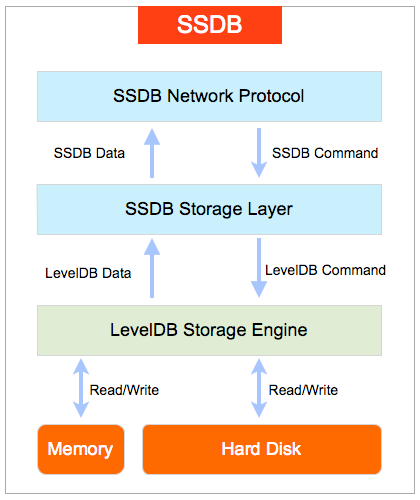
SSDB 是一个使用 C/C++ 语言开发的高性能 NoSQL 数据库, 支持 KV, list, map(hash), zset(sorted set) 等数据结构, 用来替代或者与 Redis 配合存储十亿级别列表的数据。实现上其使用了 Google 的 LevelDB作为存储引擎,SSDB 不会像 Redis 一样狂吃内存,而是将大部分数据存...... w397090770 8年前 (2017-05-27) 3122℃ 0评论7喜欢
本书作者:Rajdeep Dua、Manpreet Singh Ghotra、 Nick Pentreath,由Packt出版社于2017年04月出版,全书共532页。本书是2015年02月出版的Machine Learning with Spark的第二版。通过本书将学习到以下的知识:Get hands-on with the latest version of Spark MLCreate yo...... zz~~ 8年前 (2017-05-27) 4580℃ 0评论14喜欢
本书作者:Hanish Bansal、Saurabh Chauhan、Shrey Mehrotra,由Packt出版社于2016年4月出版,全书共486页。通过本书将学习到以下的知识:(1)、Learn different features and offering on the latest Hive(2)、Understand the working and structure of the Hive int...... zz~~ 8年前 (2017-05-26) 6494℃ 0评论22喜欢
昨天晚上,Apache Beam发布了第一个稳定版2.0.0,Apache Beam 社区声明:未来版本的发布将保持 API 的稳定性,并让 Beam 适用于企业的部署。Apache Beam 的第一个稳定版本是此社区第三个重要里程碑。Apache Beam 是在2016年2月加入 Apache 孵化器(Apache Incubator),并在...... w397090770 8年前 (2017-05-18) 1789℃ 0评论3喜欢
经过一个多月的投票,Apache Flink 1.2.1终于正式发布了。看这个版本就知道,Apache Flink 1.2.1仅仅是对 Flink 1.2.0进行一些Bug修复,不涉及重大的新功能。推荐所有的用户升级到Apache Flink 1.2.1。大家可以在自己项目的pom.xml文件引入以下依赖:<dependency>...... w397090770 8年前 (2017-05-04) 1687℃ 0评论6喜欢
Spark 的 shell 作为一个强大的交互式数据分析工具,提供了一个简单的方式来学习 API。它可以使用 Scala(在 Java 虚拟机上运行现有的 Java 库的一个很好方式) 或 Python。我们很可能会在Spark Shell模式下运行下面的测试代码:如果想及时了解Spark、Hadoop或者Hbase相关的...... w397090770 8年前 (2017-04-26) 2916℃ 0评论9喜欢
这次整理的PPT来自于2017年04月10日至11日在San Francisco进行的flink forward会议,这种性质的会议和大家熟知的Spark summit类似。本次会议的官方日程参见:http://sf.flink-forward.org/kb_day/day1/。因为原始的PPT是在http://www.slideshare.net/网站,这个网站需要翻墙...... w397090770 8年前 (2017-04-20) 2827℃ 0评论8喜欢
大家在提交MapReduce作业的时候肯定看过如下的输出:17/04/17 14:00:38 INFO mapreduce.Job: Running job: job_1472052053889_000117/04/17 14:00:48 INFO mapreduce.Job: Job job_1472052053889_0001 running in uber mode : false17/04/17 14:00:48 INFO mapreduce...... w397090770 8年前 (2017-04-18) 3751℃ 2评论11喜欢
本书由Andrew Morgan所著,全书共560页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Learn the design patterns that integrate Spark into industrialized data science pipelines 2、See how commercial data scientists de...... zz~~ 8年前 (2017-04-17) 3577℃ 2评论8喜欢
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的又一个非常大的贡献。Apache Beam的主要目标是统一批处理和流处理的编程范式,为无限,乱序,we...... w397090770 8年前 (2017-04-14) 2627℃ 0评论6喜欢

![[电子书]Machine Learning with Spark Second Edition PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_with_Spark_Second_Edition_iteblog.jpg)
![[电子书]Apache Hive Cookbook PDF下载](https://www.iteblog.com/pic/Apache_Hive_Cookbook-iteblog.jpg)




![[电子书]Mastering Spark for Data Science PDF下载](https://www.iteblog.com/pic/books/mastering-spark-data-science_iteblog.jpg)