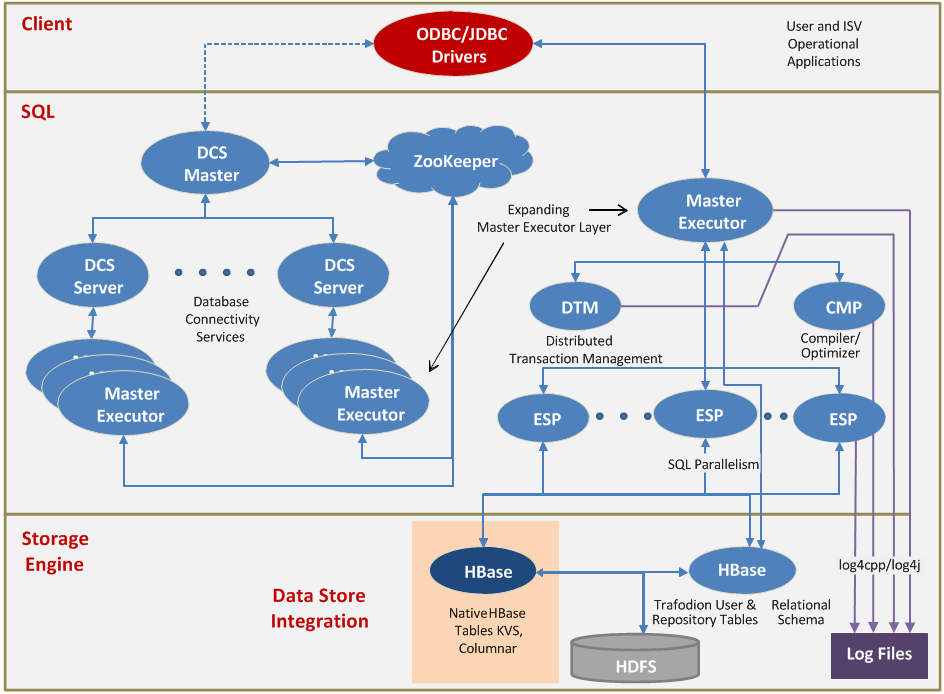
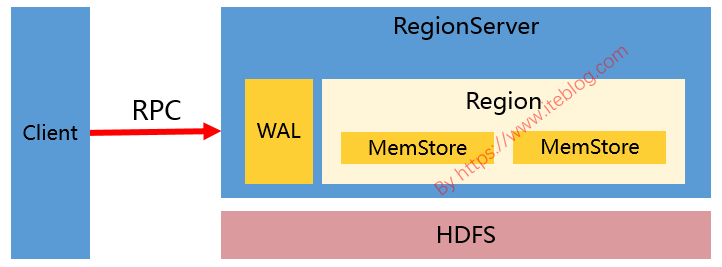
Apache HBase 是构建在 HDFS 之上的数据库,使用 HBase 我们可以随机读写存储在 HDFS 上的数据,但是我们都知道,HDFS 上的文件仅仅只支持追加(Append),其默认是不支持修改已经写好的文件。所以很多人就会问,HBase 是如何实现低延迟的读写能力呢?文本将试图介绍 HBase ...... w397090770 7年前 (2019-01-02) 2602℃ 0评论12喜欢
去年,我整理了2017年成功晋升为Apache TLP的大数据相关项目进行了整理,具体可以参见《盘点2017年晋升为Apache TLP的大数据相关项目》。现在已经进入了2019年了,我在这里给大家整理了2018年成功晋升为 Apache TLP 的大数据相关项目。2018年晋升成 TLP 的项目不多,总共四...... w397090770 7年前 (2019-01-02) 1723℃ 0评论4喜欢
在《HDFS 快照编程指南》文章中,我简单介绍了 HDFS 的快照功能。本文将介绍 HBase 快照功能,因为 HBase 的底层存储是基于 HDFS 的,所以 HBase 的快照功能也是依赖 HDFS 快照的知识。HBase 快照功能是从 HBase 0.95.0 开始引入的,详见 HBASE-50。如果想及时了解Spark、...... w397090770 7年前 (2019-01-01) 2769℃ 0评论9喜欢
我们知道,一张 HBase 表包含一个或多个列族。HBase 的官方文档中关于 HBase 表的列族的个数有两处描述:A typical schema has between 1 and 3 column families per table. HBase tables should not be designed to mimic RDBMS tables. 以及 HBase currently does not do ...... w397090770 7年前 (2019-01-01) 4606℃ 1评论13喜欢
本文来自本人于2018年12月25日在 HBase生态+Spark社区钉钉大群直播,本群每周二下午18点-19点之间进行 HBase+Spark技术分享。加群地址:https://dwz.cn/Fvqv066s。本文 PPT 下载:关注 iteblog_hadoop 微信公众号,并回复 HBase_Rowkey 关键字获取。为什么Rowkey这么重要R...... w397090770 7年前 (2018-12-25) 7604℃ 0评论29喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,dataArtisans(Apache Flink 商业母公司),华为、腾讯、滴滴、美团以及字节跳动等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可...... w397090770 7年前 (2018-12-22) 4135℃ 0评论17喜欢
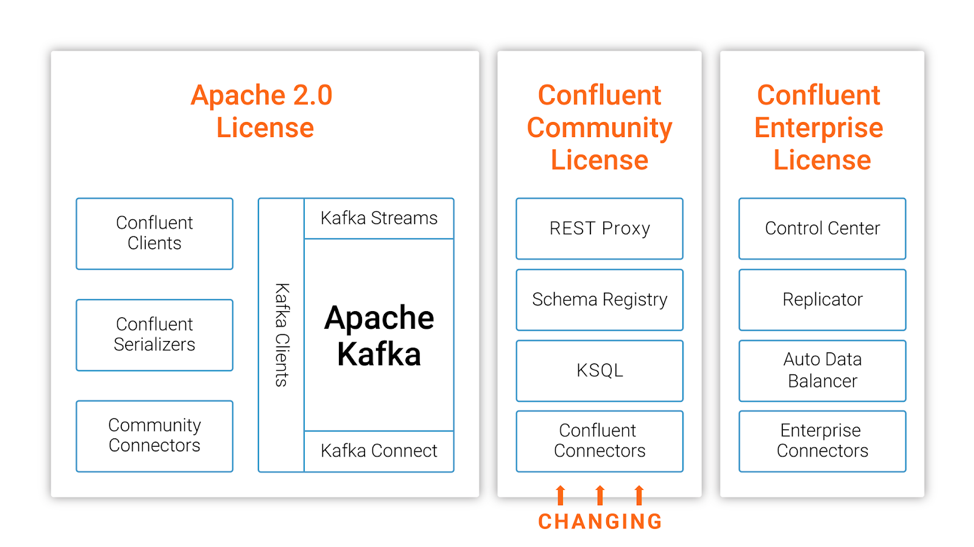
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache ...... w397090770 7年前 (2018-12-15) 2057℃ 0评论3喜欢
随着图像分类(image classification)和对象检测(object detection)的深度学习框架的最新进展,开发者对 Apache Spark 中标准图像处理的需求变得越来越大。图像处理和预处理有其特定的挑战 - 比如,图像有不同的格式(例如,jpeg,png等),大小和颜色,并且没有简单的方...... w397090770 7年前 (2018-12-13) 2526℃ 0评论4喜欢
Apache Avro 是一种流行的数据序列化格式。它广泛用于 Apache Spark 和 Apache Hadoop 生态系统,尤其适用于基于 Kafka 的数据管道。从 Apache Spark 2.4 版本开始,Spark 为读取和写入 Avro 数据提供内置支持。新的内置 spark-avro 模块最初来自 Databricks 的开源项目Avro...... w397090770 7年前 (2018-12-11) 3312℃ 0评论9喜欢
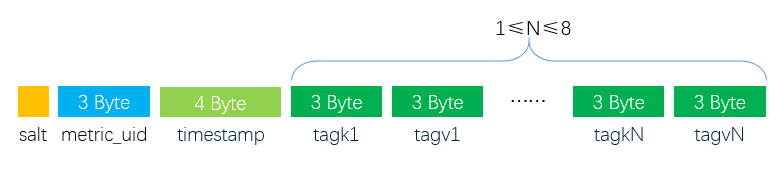
我们在 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章中已经简单介绍了 OpenTSDB 的 RowKey 设计的思路,并简单介绍了列簇以及列名的组成。本文将比较详细的介绍 OpenTSDB 在 HBase 的数据存储模型。OpenTSDB RowKey 设计关于 OpenTSDB 的 RowKey 为什么这么设计...... w397090770 7年前 (2018-12-05) 3050℃ 0评论3喜欢