今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的...... w397090770 6年前 (2019-08-13) 5714℃ 2评论33喜欢
我们在 Apache Spark DataSource V2 介绍及入门编程指南(上) 文章中介绍了 Apache Spark DataSource V1 的不足,所以才有了 Data Source API V2 的诞生。Data Source API V2为了解决 Data Source V1 的一些问题,从 Apache Spark 2.3.0 版本开始,社区引入了 Data Sour...... w397090770 6年前 (2019-08-13) 4219℃ 1评论9喜欢
Data Source API 定义如何从存储系统进行读写的相关 API 接口,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。这些 API 非常适合用户在 Spark 中使用 RDD 编程的时候使用。使用这些 API 进行编程虽然能够解决我们的问题,但是对用户来说使用成本还是挺高的,...... w397090770 6年前 (2019-08-13) 3723℃ 0评论3喜欢
美国当地时间2019年8月5日,惠普企业(Hewlett Packard Enterprises,纽约证券交易所股票代码:HPE)宣布收购 MapR Technologies Inc. 的业务资产!如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop此交易包括 MapR 的技术,知识产...... w397090770 6年前 (2019-08-12) 1270℃ 0评论1喜欢
Spark SQL 是 Spark 最新且技术最复杂的组件之一。它同时支持 SQL 查询和新的 DataFrame API。Spark SQL 的核心是 Catalyst 优化器,它以一种全新的方式利用高级语言的特性(例如:Scala 的模式匹配和 Quasiquotes ①)构建一个可扩展的查询优化器。最近我们在 SIGMOD 2015 ...... w397090770 6年前 (2019-07-21) 3388℃ 0评论5喜欢
2019 年 7 月 17 日,Cloudera 官方博客发文开源了一个内部研发使用很久的大数据存储和通用计算平台交叉的新项目 YuniKorn。Yunikorn 是一个新的独立通用资源调度程序,负责为大数据工作负载分配/管理资源,包括批处理作业和长时间运行的服务。介绍YuniKorn 是一种轻量级...... w397090770 6年前 (2019-07-17) 3914℃ 0评论0喜欢
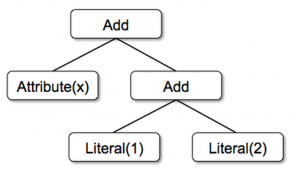
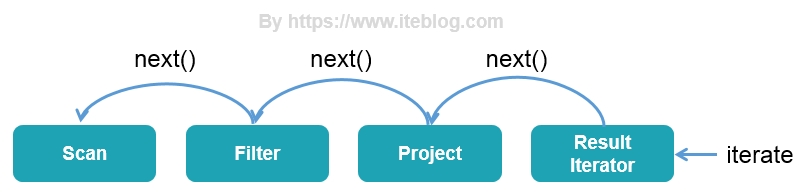
终于到最后一篇了,我们在前面两篇文章中《一条 SQL 在 Apache Spark 之旅(上)》 和 《一条 SQL 在 Apache Spark 之旅(中)》 介绍了 Spark SQL 之旅的 SQL 解析、逻辑计划绑定、逻辑计划优化以及物理计划生成阶段,本文我们将继续接上文,介绍 Spark SQL 的全阶段代码生...... w397090770 6年前 (2019-06-19) 9255℃ 0评论17喜欢
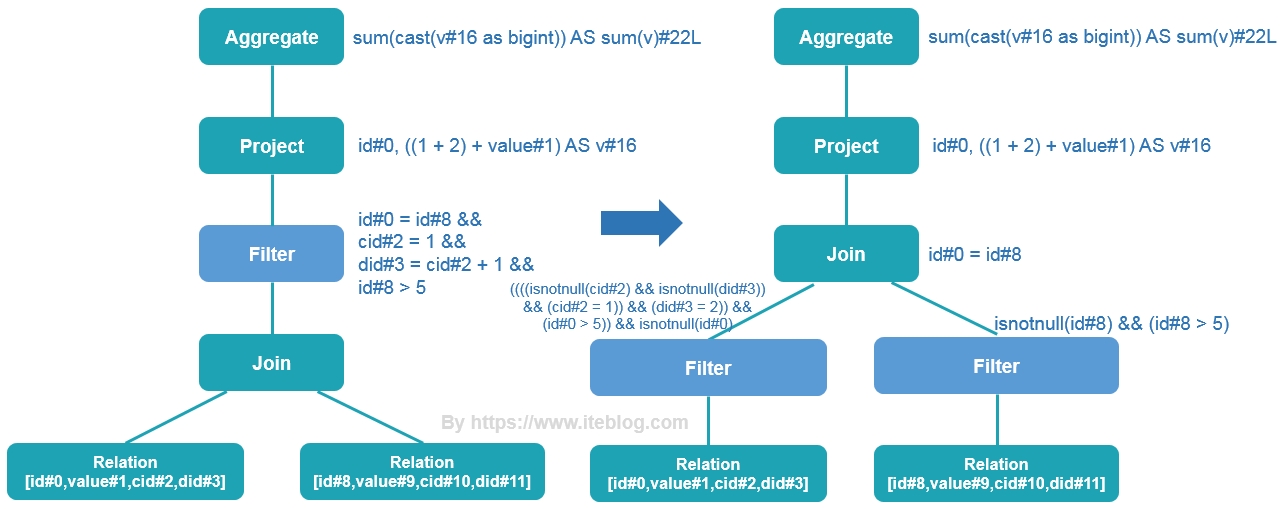
在 《一条 SQL 在 Apache Spark 之旅(上)》 文章中我们介绍了一条 SQL 在 Apache Spark 之旅的 Parser 和 Analyzer 两个过程,本文接上文继续介绍。优化逻辑计划阶段 - Optimizer在前文的绑定逻辑计划阶段对 Unresolved LogicalPlan 进行相关 transform 操作得到了 Anal...... w397090770 6年前 (2019-06-18) 5841℃ 4评论21喜欢
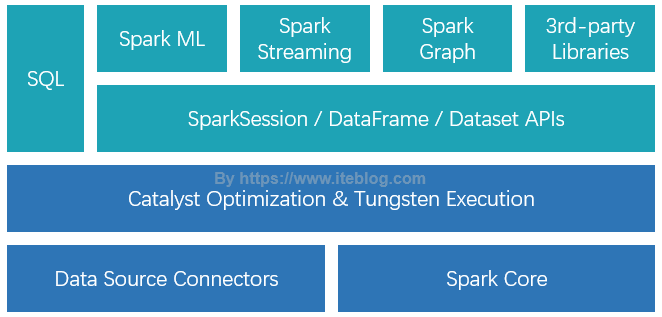
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungste...... w397090770 6年前 (2019-06-12) 11104℃ 0评论31喜欢
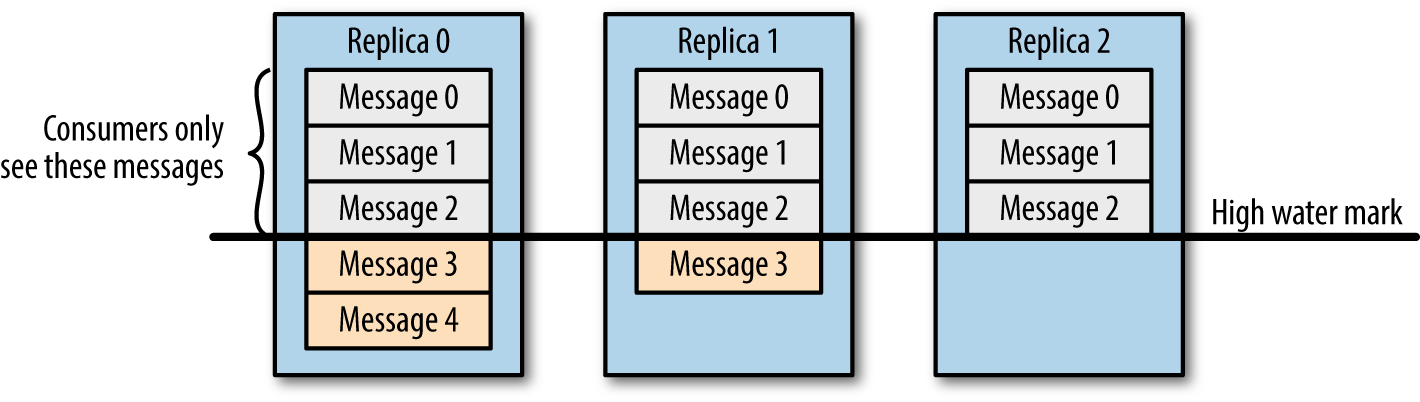
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本...... w397090770 6年前 (2019-06-11) 12998℃ 2评论42喜欢