在高德纳的计算机程序设计艺术中,有如下问题:可否在一未知大小的集合中,随机取出一元素?。或者是Google面试题: I have a linked list of numbers of length N. N is very large and I don’t know in advance the exact value of N. How can I most efficiently write a function that will return k completely random numbers from the list(中文简化的意思就是:在不知道文件总行 w397090770 9年前 (2015-11-09) 10141℃ 0评论16喜欢
为了提高本博客的用户体验,我于去年七月写了一份代码,将博客与微信公共帐号关联起来(可以参见本博客),用户可以在里面输入相关的关键字(比如new、rand、hot),但是那时候关键字有限制,只能对文章的分类进行搜索。不过,今天我修改了自动回复功能相关代码,目前支持对任意的关键字进行全文搜索,其结果相关与调用 w397090770 9年前 (2015-11-07) 2053℃ 0评论8喜欢
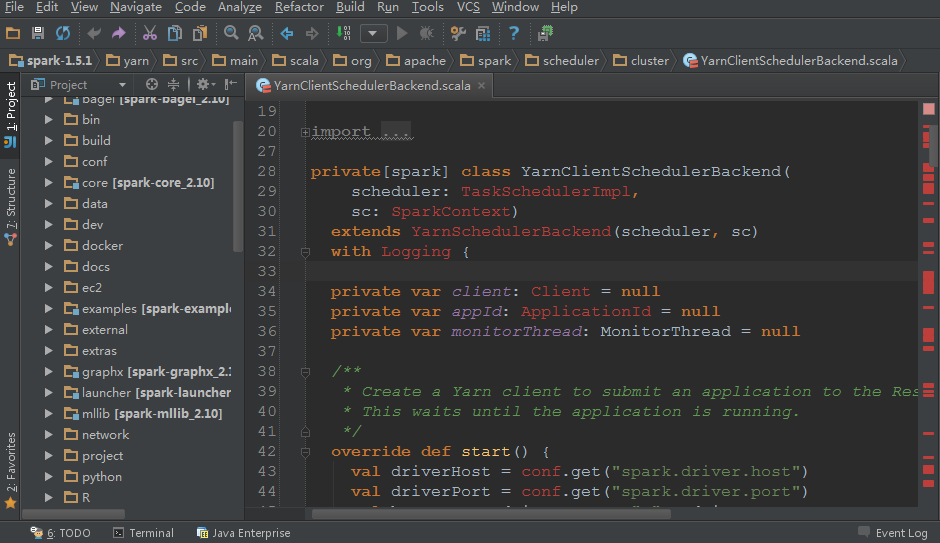
我们在学习或者使用Spark的时候都会选择下载Spark的源码包来加强Spark的学习。但是在导入Spark代码的时候,我们会发现yarn模块的相关代码总是有相关类依赖找不到的错误(如下图),而且搜索(快捷键Ctrl+N)里面的类时会搜索不到!这给我们带来了很多不遍。。 本文就是来解决这个问题的。我使用的是Idea IDE工具阅读代 w397090770 9年前 (2015-11-07) 8951℃ 4评论11喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 9年前 (2015-11-06) 7954℃ 0评论9喜欢
在Scala中一个很强大的功能就是模式匹配,本文并不打算介绍模式匹配的概念以及如何使用。本文的主要内容是讨论Scala模式匹配泛型类型擦除问题。先来看看泛型类型擦除是什么情况:scala> def test(a:Any) = a match { | case a :List[String] => println("iteblog is ok"); | case _ => |} 按照代码的意思应该是匹配L w397090770 9年前 (2015-10-28) 6327℃ 0评论11喜欢
我们在开发网站的时候一般都会分header、main、side、footer。这些模块分别包含了各自公用的信息,比如header一般都是本网站所有页面需要引入的模块,里面一般都是放置菜单等信息;而footer一般是放在网站所有页面的底部。当网页的内容比较多的时候,我们可以看到footer一般都是在页面的底部。但是,当页面的内容不足以填满一 w397090770 9年前 (2015-10-28) 4449℃ 0评论8喜欢
Spark Data Source API是从Spark 1.2开始提供的,它提供了可插拔的机制来和各种结构化数据进行整合。Spark用户可以从多种数据源读取数据,比如Hive table、JSON文件、Parquet文件等等。我们也可以到http://spark-packages.org/(这个网站貌似现在不可以访问了)网站查看Spark支持的第三方数据源工具包。本文将介绍新的Spark数据源包,通过它我们 w397090770 9年前 (2015-10-21) 3769℃ 0评论4喜欢
你可能会在Scala中经常使用for循环已经,所以理解Scala编译器是如何解析for循环语句是非常重要的。我们记住以下四点规则即可: 1、对集合进行简单的for操作,Scala编译器会将它翻译成对集合进行foreach操作; 2、带有guard的for循环,编译器会将它翻译成一序列的withFilter操作,紧接着是foreach操作; 3、带有yield的for w397090770 9年前 (2015-10-20) 3940℃ 0评论6喜欢
我们知道,在Spark中创建RDD的创建方式大概可以分为三种:(1)、从集合中创建RDD;(2)、从外部存储创建RDD;(3)、从其他RDD创建。 而从集合中创建RDD,Spark主要提供了两中函数:parallelize和makeRDD。我们可以先看看这两个函数的声明:[code lang="scala"]def parallelize[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParalle w397090770 9年前 (2015-10-09) 48209℃ 0评论60喜欢
本页面不再更新,请移步到 《2018 最新 hosts 文件持续更新》如果之前的hosts文件还有效可以不更新;由于大家使用的带宽种类,地区,被墙的程度不一样,所以有些地区使用本Hosts文件可能仍然无法使用Google;光靠修改Hosts文件是无法观看youtube里面的视频,重要的事说三遍:通过本hosts文件可以打开youtube网站,但是无法观看 w397090770 9年前 (2015-09-25) 193810℃ 376喜欢






![最新可访问Google的Hosts文件[最新更新]](https://www.iteblog.com/pic/host.jpg)