Apache Kafka 是一个开源流处理平台,如今有超过30%的财富500强企业使用该平台。Kafka 有很多特性使其成为事件流平台(event streaming platform)的事实上的标准。在这篇博文中,我将介绍每个 Kafka 开发者都应该知道的五件事,这样在使用 Kafka 就可以避免很多问题。Tip #1 理解消息传递和持久性保证对于数据持久性(data durability), w397090770 3年前 (2021-04-18) 949℃ 0评论4喜欢
iceberg 详细设计Apache iceberg 是Netflix开源的全新的存储格式,我们已经有了parquet、orc、arvo等非常优秀的存储格式以后,Netfix为什么还要设计出iceberg呢?和parquet、orc等文件格式不同, iceberg在业界被称之为Table Foramt,parquet、orc、avro等文件等格式帮助我们高效的修改、读取单个文件;同样Table Foramt帮助我们高效的修改和读取一类文件 w397090770 3年前 (2021-04-15) 2135℃ 0评论6喜欢
迁移指南如果从 0.5.3 以下版本迁移,请检查这个版本后面的其他版本的升级说明。如果需要升级到 0.8 版本,请参阅 0.6.0 版本的升级指南,因为本版本没有引入新的表版本(table versions)HoodieRecordPayload接口不建议使用现有方法,而推荐使用新方法,该方法还允许我们在运行时传递属性。 鼓励用户从不建议使用的方法中迁移 w397090770 3年前 (2021-04-14) 848℃ 0评论2喜欢
Apache Kafka 的核心设计是日志(Log)—— 一个简单的数据结构,使用顺序操作。以日志为中心的设计带来了高效的磁盘缓冲和 CPU 缓存使用、预取、零拷贝数据传输和许多其他好处,从而使 Kafka 能够提供高效率和吞吐量的功能。对于那些刚接触 Kafka 的人来说,主题(topic)以及提交日志的底层实现通常是他们学习的第一件事。但 w397090770 3年前 (2021-04-11) 711℃ 0评论4喜欢
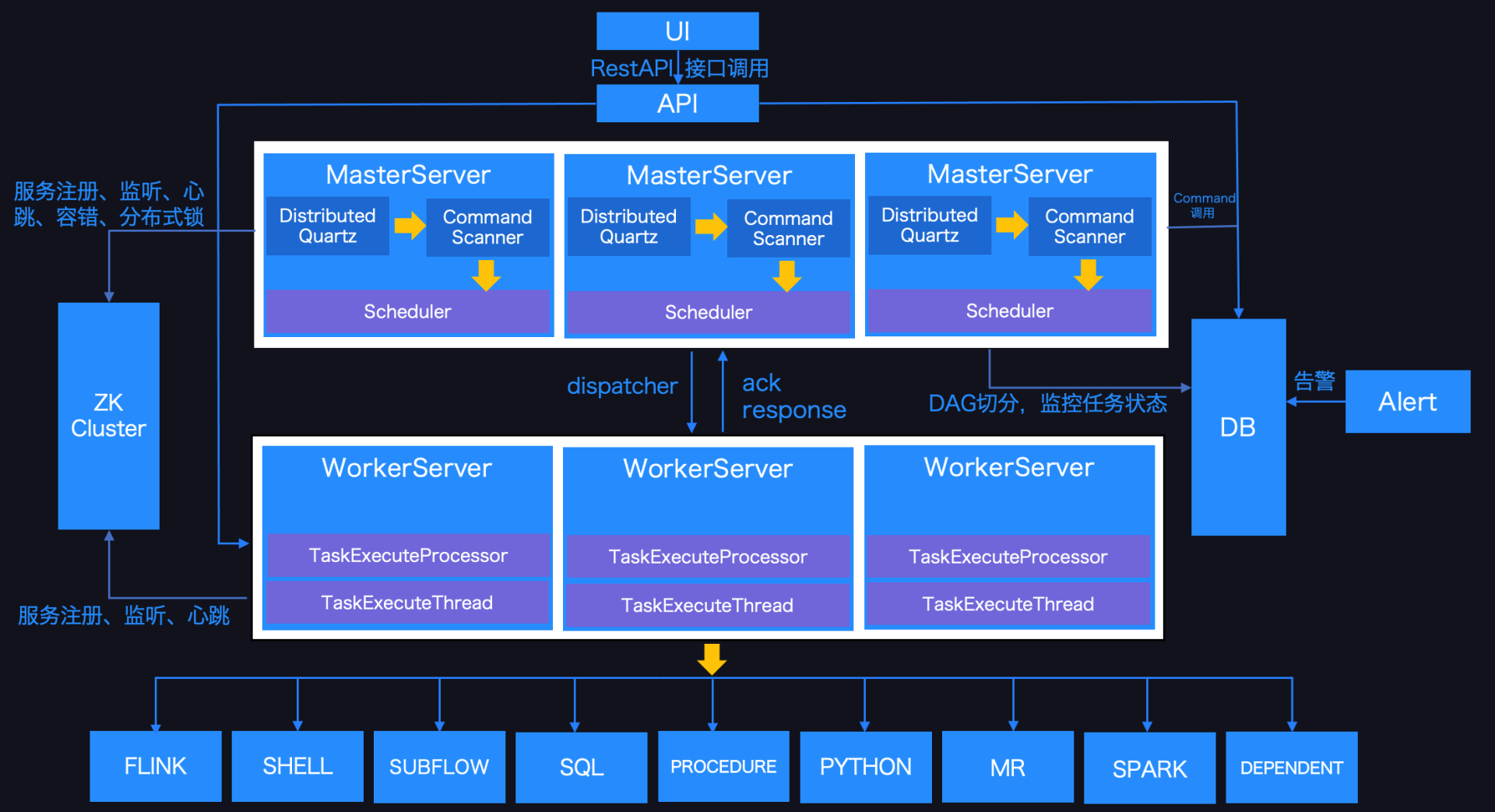
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于北京时间 2021年4月9日在官方渠道宣布Apache DolphinScheduler 毕业成为Apache顶级项目。这是首个由国人主导并贡献到 Apache 的大数据工作流调度领域的顶级项目。DolphinScheduler™ 已经是联通、IDG、IBM、京东物流、联想、新东方、诺基亚、360、顺丰和腾讯等 400+ 公司在使用 w397090770 3年前 (2021-04-09) 1726℃ 0评论3喜欢
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, w397090770 3年前 (2021-04-05) 1183℃ 0评论4喜欢
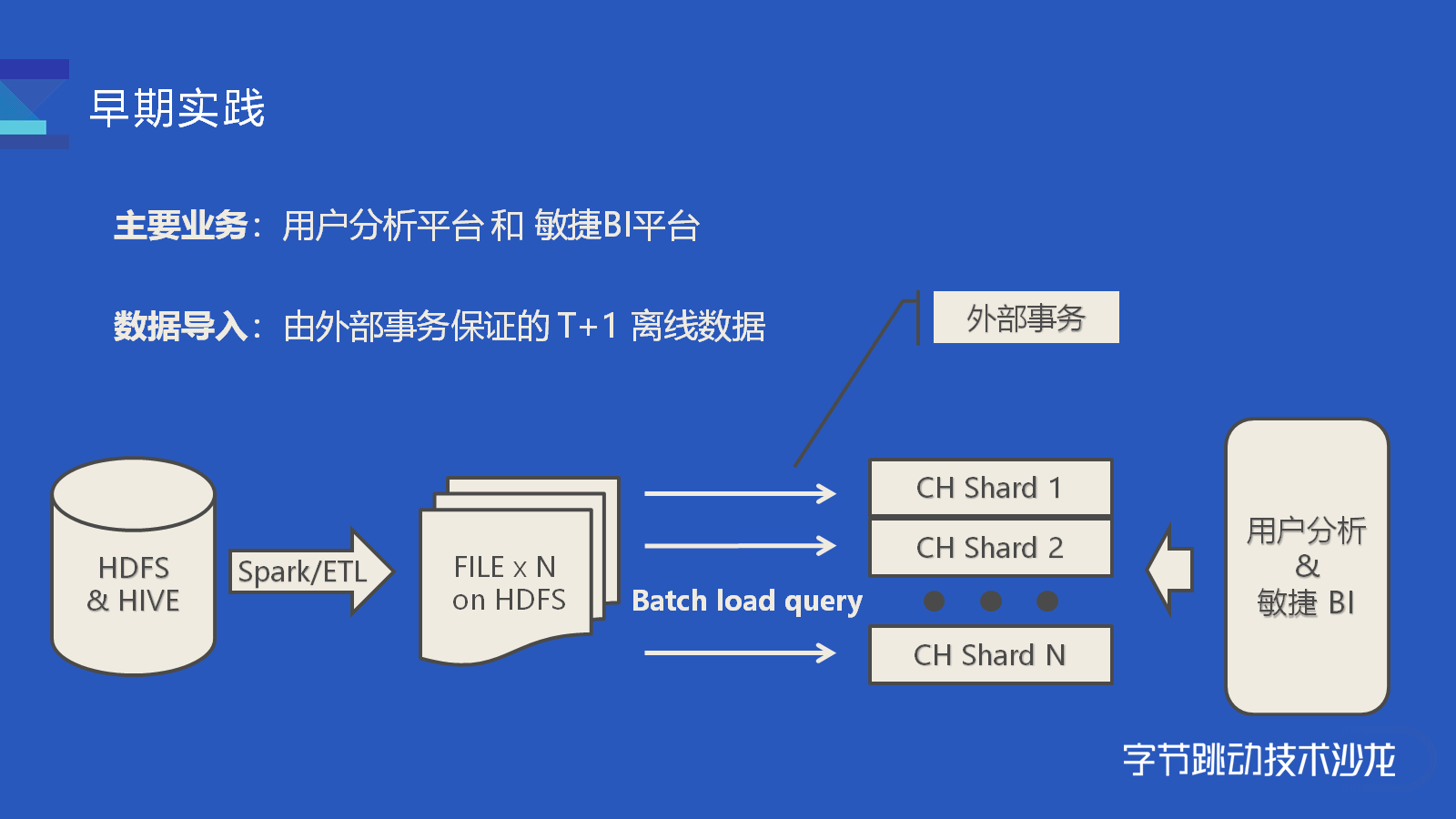
讲师:郭映中 字节跳动 ClickHouse 研发工程师此次分享分为三部分内容,第一部分通过讲解推荐和广告业务的两个典型案例,穿插介绍字节内部相应的改进。第二部分会介绍典型案例中未覆盖到的改进和经验。第三部分会提出目前的不足和未来的改进计划。早期实践如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注 w397090770 3年前 (2021-03-05) 4603℃ 0评论5喜欢
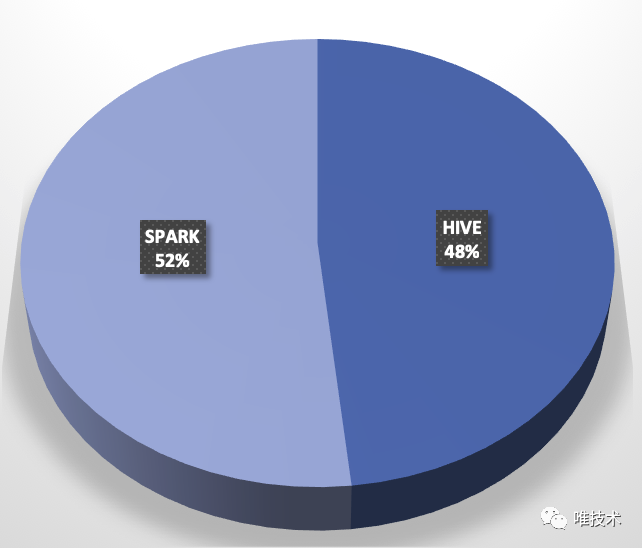
Hive 设计之初,就被定位一款离线数仓产品,虽然Hortonworks喊出了Make Apache Hive 100x Faster的牛逼口号,也在上面做了大量的优化,然而性能提升依旧不大。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆而随着OPPO数据量一步步的增多,动辄运行几个小时的hive再也满足不了交互查询的需求,因此我们 w397090770 3年前 (2021-03-05) 917℃ 0评论6喜欢
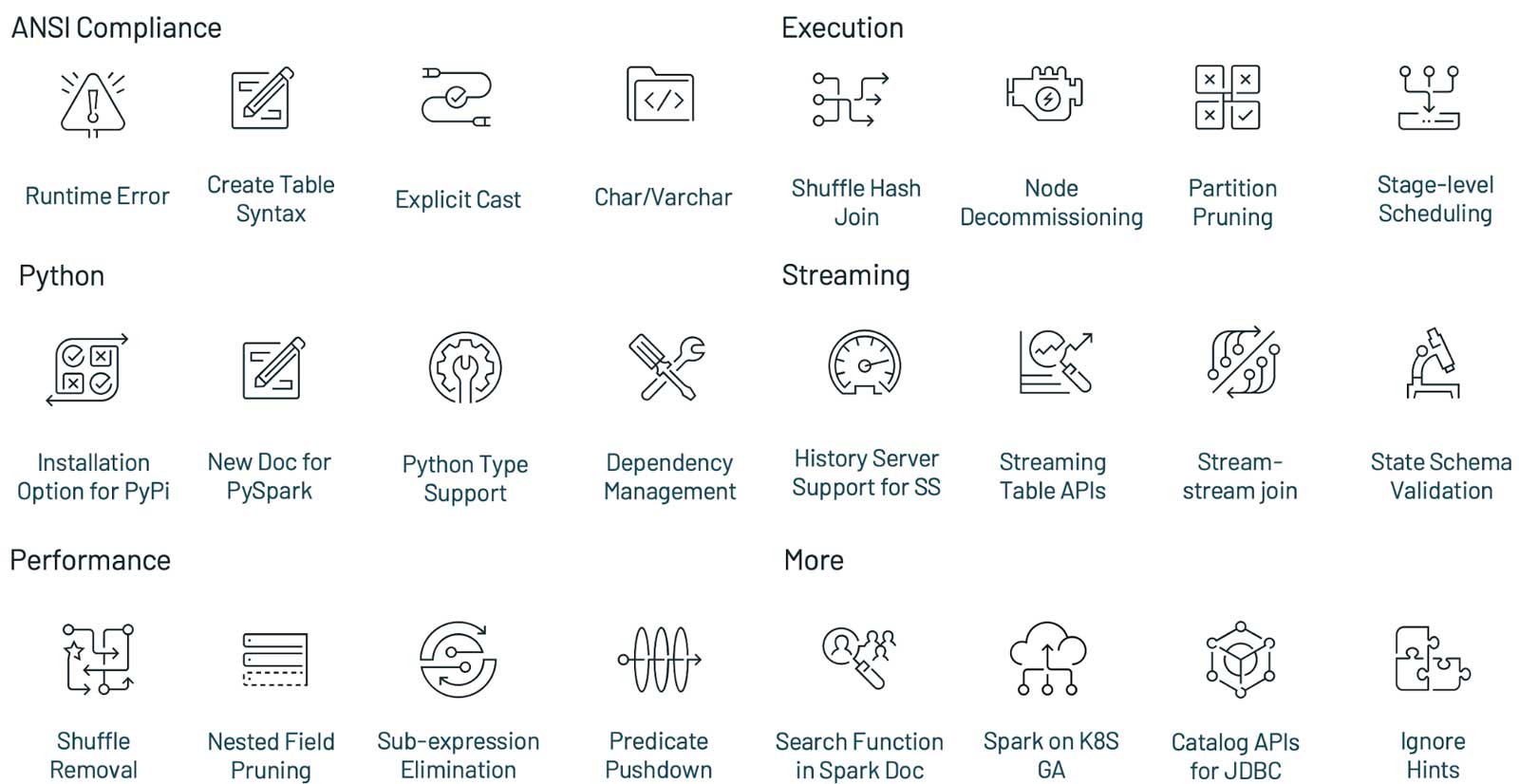
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming注意,由于技术上的原因,Apache Spark 没有发布 3.1.0 版 w397090770 3年前 (2021-03-03) 2168℃ 0评论9喜欢
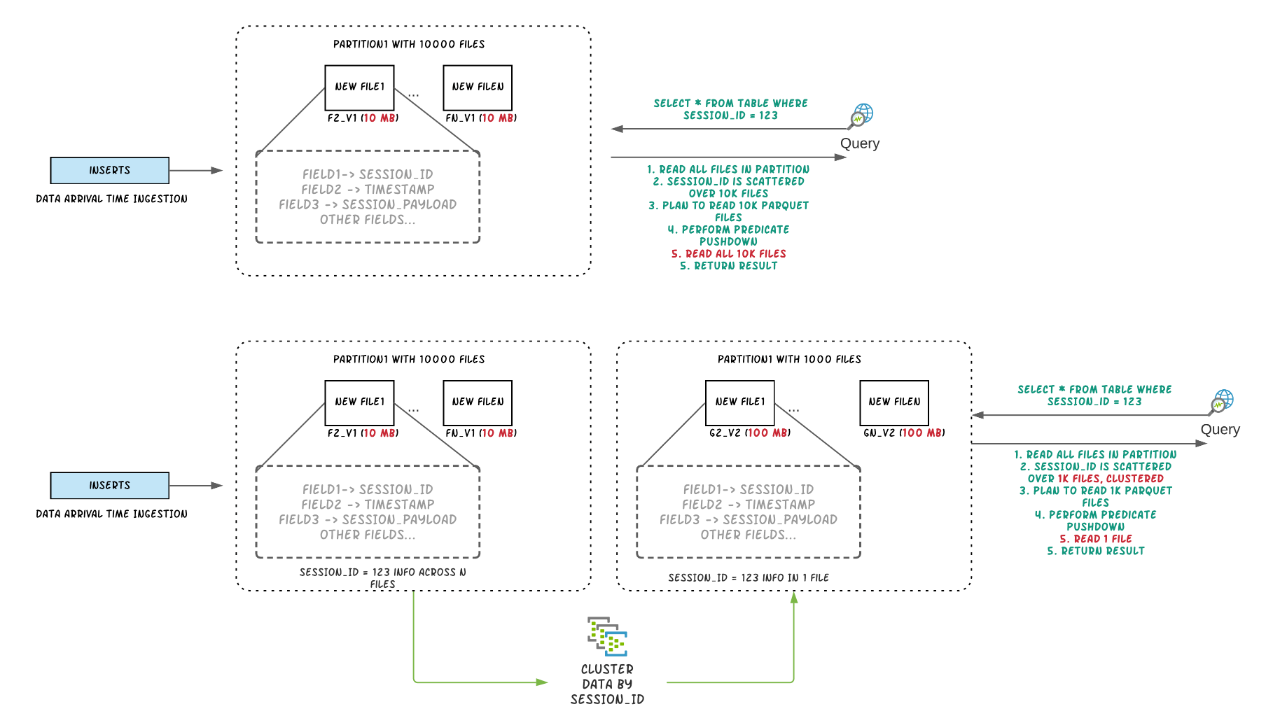
背景Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据。在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查询性能下降。在摄取过程中通常会根据时间在同一位置放置数据,但如果把查询频 w397090770 3年前 (2021-02-24) 1406℃ 0评论4喜欢