Apache HAWQ(incubating)的第一个版本受益于ASF(Apache software foundation)组织,通过将MPP(Massively Parallel Processing)和批处理系统(batch system)有效的结合,在性能上有了很大的提升,并且克服了一些关键的限制问题。一个新的重新设计的执行引擎在以下的几个问题在总体系统性能上有了很大的提高:硬件错误引起的短板问题(straggler)并发限制 w397090770 3年前 (2021-06-18) 895℃ 0评论0喜欢
作者:小君,部门:技术中台/数据中台前言随着实时技术的不断发展和商家实时应用场景的不断丰富,有赞在实时数仓建设方面做了大量的尝试和实践。本文主要分享有赞在建设实时数仓过程中所沉淀的经验,内容包括以下五个部分: 建设背景 应用场景 方案设计 项目应用 未来展望建设背景 实时需求日趋迫 zz~~ 3年前 (2021-06-10) 274℃ 0评论0喜欢
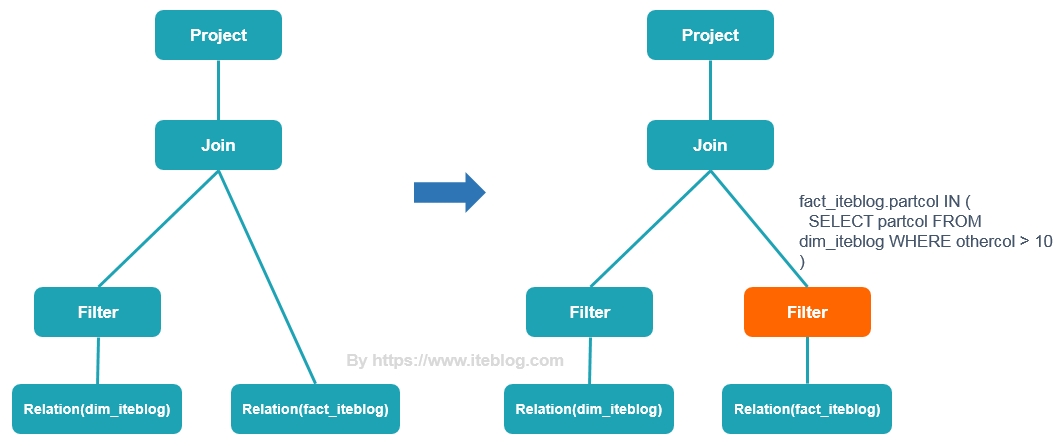
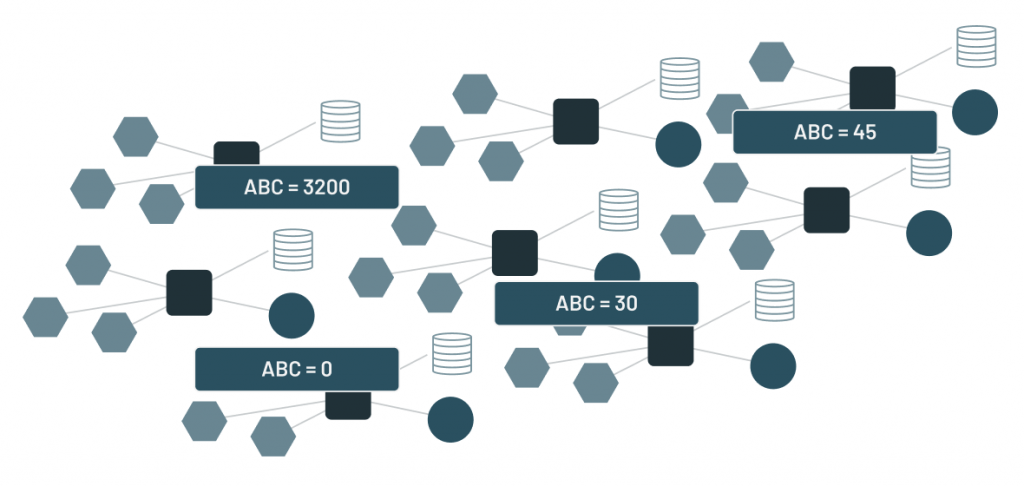
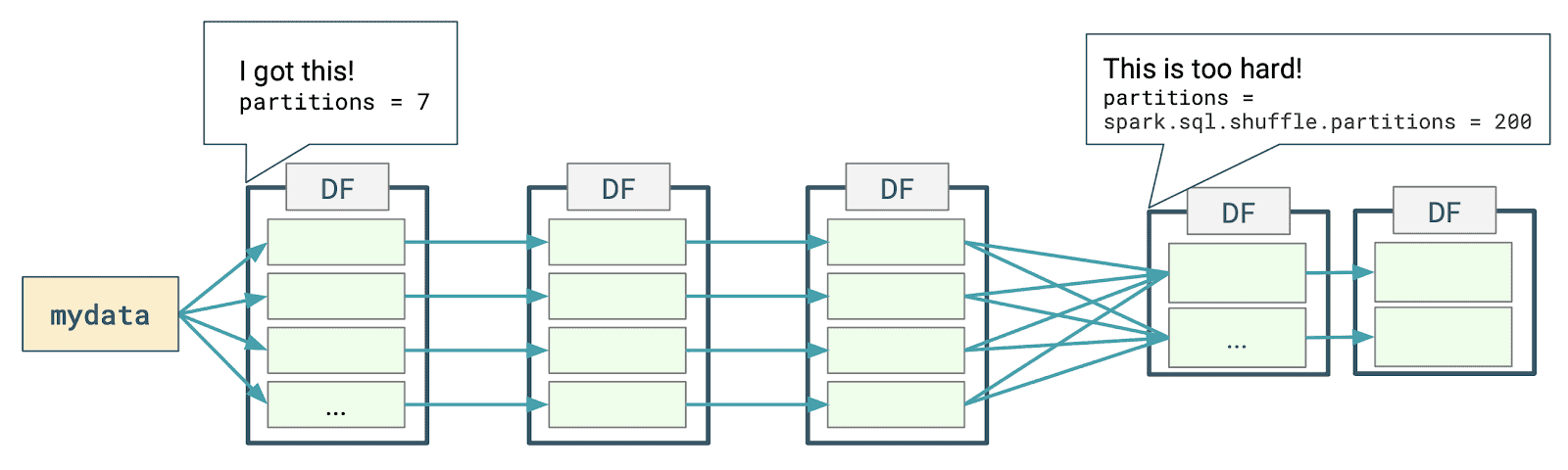
早在2005年,Oracle 数据库就支持比较丰富的 dynamic filtering 功能,而 Spark 和 Presto 在最近版本才开始支持这个功能。本文将介绍 Presto 动态过滤的原理以及具体使用。Apache Spark 的动态分区裁减Apache Spark 3.0 给我们带来了许多的新特性用于加速查询性能,其中一个就是动态分区裁减(Dynamic Partition Pruning,DPP),所谓的动态分区裁剪就 w397090770 3年前 (2021-06-01) 1236℃ 0评论2喜欢
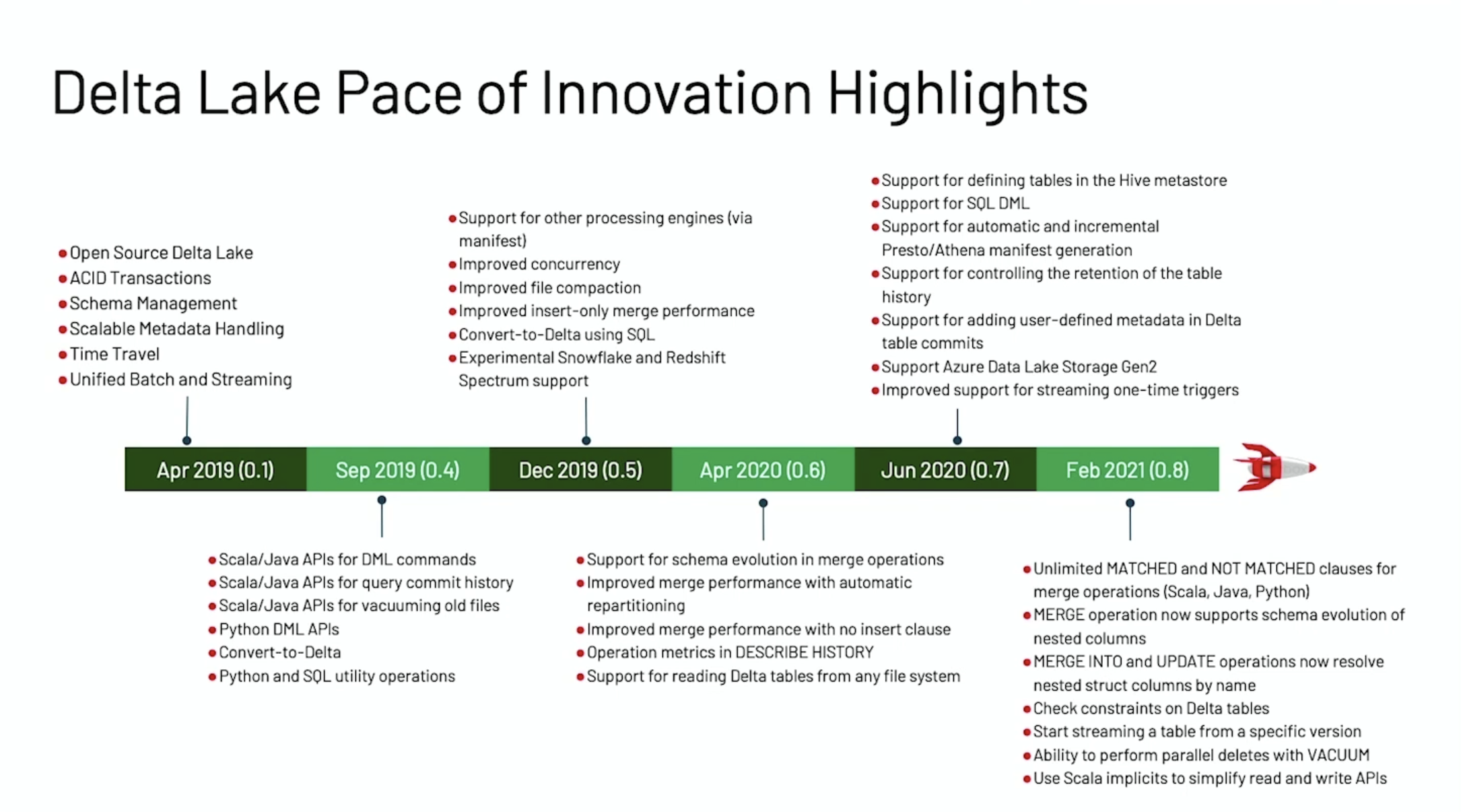
赶在 Data + AI Summit 2021 之前,Delta Lake 1.0.0 重磅发布,这个版本是基于 Spark 3.1 的,带来了许多新特性。本文将结合 Michael Armbrust 大牛在 Data + AI Summit 2021 的演讲《Announcing Delta Lake 1.0》来介绍 Delta Lake 1.0.0 版本的一些重要的新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Delta Lake 0.1 w397090770 3年前 (2021-05-27) 804℃ 0评论1喜欢
本书作者 Denny Lee, Tathagata Das, Vini Jaiswal,预计2022年4月出版,出版社 O'Reilly Media, Inc.,ISBN:9781098104528分析和机器学习模型的好坏取决于它们所依赖的数据。查询处理过的数据并从中获得见解需要一个健壮的数据管道——以及一个有效的存储解决方案,以确保数据质量、数据完整性和性能。本指南向您介绍 Delta Lake,这是一种开 w397090770 3年前 (2021-05-27) 526℃ 0评论2喜欢
本文是 Forest Rim Technology 数据团队撰写的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被称为是数据仓库之父,最早的数据仓库概念提出者,被《计算机世界》评为计算机行业历史上最具影响力的十大人物之一。原始数据的挑战随着大量应用程序的出现,产生了相同的数据在不同地方出现不同值的情况。为了做出决定,用户必须找 w397090770 3年前 (2021-05-25) 553℃ 0评论0喜欢
在几乎所有处理复杂数据的领域,Spark 已经迅速成为数据和分析生命周期团队的事实上的分布式计算框架。Spark 3.0 最受期待的特性之一是新的自适应查询执行框架(Adaptive Query Execution,AQE),该框架解决了许多 Spark SQL 工作负载遇到的问题。AQE 在2018年初由英特尔和百度组成的团队最早实现。AQE 最初是在 Spark 2.4 中引入的, Spark 3.0 做 w397090770 3年前 (2021-05-23) 1059℃ 0评论2喜欢
Apache Spark 3.1.x 版本发布到现在已经过了两个多月了,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming更多详情请参见这里。在这篇博文中,我们总结了3.1版本中 w397090770 3年前 (2021-05-16) 674℃ 0评论2喜欢
FFmpeg 是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,采用 LGPL 或 GPL 许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库 libavcodec,为了保证高可移植性和编解码质量,libavcodec 里很多 code 都是从头开发的。如果想及时了解Spark、Hadoop或者HBase相 w397090770 3年前 (2021-04-30) 702℃ 0评论2喜欢
With MongoDB 3.6 the query language gains a new level of expressivity: you can now make use of aggregation expressions in a query using the $expr operator. This feature allows you to take full advantage of all expression operators within all queries, much of which previously had to be done within application logic or was restricted to the aggregation pipeline. $expr offers better performance than the $where operator, which while still a w397090770 3年前 (2021-04-27) 2246℃ 0评论2喜欢