《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 9年前 (2015-05-15) 4777℃ 0评论3喜欢
如果你想知道Hadoop作业运行日志,可以查看这里《Hadoop日志存放路径详解》 在很多情况下,我们需要查看driver和executors在运行Spark应用程序时候产生的日志,这些日志对于我们调试和查找问题是很重要的。 Spark日志确切的存放路径和部署模式相关: (1)、如果是Spark Standalone模式,我们可以直接在Master UI界 w397090770 9年前 (2015-05-14) 39483℃ 6评论16喜欢
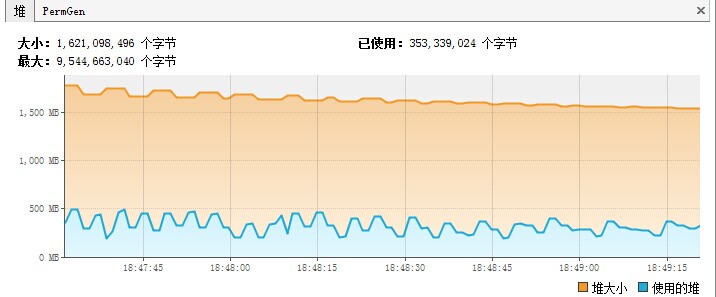
jvisualvm工具JDK自带的一个监控工具,该工具是用来监控java运行程序的cpu、内存、线程等的使用情况,并且使用图表的方式监控java程序、还具有远程监控能力,不失为一个用来监控Java程序的好工具。 同样,我们可以使用jvisualvm来监控Spark应用程序(Application),从而可以看到Spark应用程序堆,线程的使用情况,从而根据这 w397090770 9年前 (2015-05-13) 10646℃ 0评论9喜欢
在本博客的《Spark Metrics配置详解》文章中介绍了Spark Metrics的配置,其中我们就介绍了Spark监控支持Ganglia Sink。Ganglia是UC Berkeley发起的一个开源集群监视项目,主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性 w397090770 9年前 (2015-05-11) 13785℃ 1评论13喜欢
在提交作业的时候出现了以下的异常信息:[code lang="scala"]2015-05-05 11:09:28,071 INFO [Driver] - Attempting to load checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-14307949860002015-05-05 11:09:28,076 WARN [Driver] - Error reading checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-1430794986000java.io.InvalidClassException: org.apache.spark.streaming w397090770 9年前 (2015-05-10) 18727℃ 0评论7喜欢
在几年前,Oracle宣布不再维护Java 6的更新(看这里http://www.computerworld.com/article/2494112/application-security/oracle-to-stop-patching-java-6-in-february-2013.html),那么Java 6发现的新bug Oracle公司也就不再会去修改,这对用户来说就是不好的消息。 在前几天发布的Hadoop 2.7.0 (《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》)中的一个重要的 w397090770 9年前 (2015-05-06) 7382℃ 1评论4喜欢
和Hadoop类似,在Spark中也存在很多的Metrics配置相关的参数,它是基于Coda Hale Metrics Library的可配置Metrics系统,我们可以通过配置文件进行配置,通过Spark的Metrics系统,我们可以把Spark Metrics的信息报告到各种各样的Sink,比如HTTP、JMX以及CSV文件。Spark的Metrics系统目前支持以下的实例:master:Spark standalone模式的master进程;worker:S w397090770 9年前 (2015-05-05) 14122℃ 0评论15喜欢
上海Spark Meetup第四次聚会将于2015年5月16日在小沃科技有限公司(原中国联通应用商店运营中心)举办。本次聚会特别添加了抽奖环节,凡是参加了问卷调查并在当天到场的同学们都有机会中奖。奖品由英特尔亚太研发有限公司赞助。大会主题 Opening Keynote 沈洲 小沃科技有限公司副总经理,上海交通大学计算机专 w397090770 9年前 (2015-05-05) 3450℃ 0评论2喜欢
一、活动时间 5月10日下午14:00-18:00二、活动地点北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼1层 地图: http://j.map.baidu.com/yVWh0三、活动内容: 1、鲁小亿 美国俄亥俄州立大学计算机科学与工程系 Senior Research Associate,演讲主题:<spark & RDMA> 2、董旭 滴滴打车 高级软件工程师,高性能计算负责 w397090770 9年前 (2015-05-05) 2941℃ 0评论6喜欢
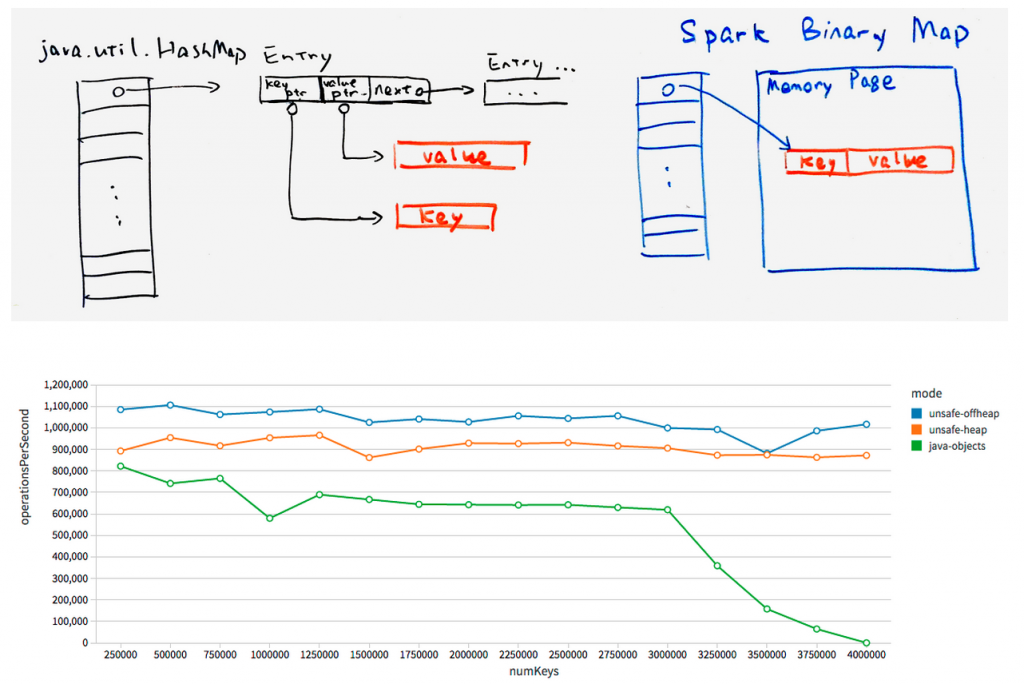
在之前的博文中,我们回顾和总结了2014年Spark在性能提升上所做的努力。本篇博文中,我们将为你介绍性能提升的下一阶段——Tungsten。在2014年,我们目睹了Spark缔造大规模排序的新世界纪录,同时也看到了Spark整个引擎的大幅度提升——从Python到SQL再到机器学习。 Tungsten项目将是Spark自诞生以来内核级别的最大改动,以 w397090770 9年前 (2015-05-04) 4791℃ 1评论4喜欢