早上时间匆忙,我将于晚点时间详细地介绍Spark 1.4的更新,请关注本博客。 Apache Spark 1.4.0的新特性可以看这里《Apache Spark 1.4.0新特性详解》。 Apache Spark 1.4.0于美国时间的2015年6月11日正式发布。Python 3支持,R API,window functions,ORC,DataFrame的统计分析功能,更好的执行解析界面,再加上机器学习管道从alpha毕业成 w397090770 9年前 (2015-06-12) 4673℃ 0评论11喜欢
我(不是博主,这里的我指的是Shivaram Venkataraman)很高兴地宣布即将发布的Apache Spark 1.4 release将包含SparkR,它是一个R语言包,允许数据科学家通过R shell来分析大规模数据集以及交互式地运行Jobs。 R语言是一个非常流行的统计编程语言,并且支持很多扩展以便支持数据处理和机器学习任务。然而,R中交互式地数据分析常 w397090770 9年前 (2015-06-10) 8209℃ 0评论12喜欢
在Spark 1.4中引入了REST API,这样我们可以像Hadoop中REST API一样,很方便地获取一些信息。这个ISSUE在https://issues.apache.org/jira/browse/SPARK-3644里面首先被提出,已经在Spark 1.4加入。 Spark的REST API返回的信息是JSON格式的,开发者们可以很方便地通过这个API来创建可视化的Spark监控工具。目前这个API支持正在运行的应用程序,也支持 w397090770 9年前 (2015-06-10) 15640℃ 0评论8喜欢
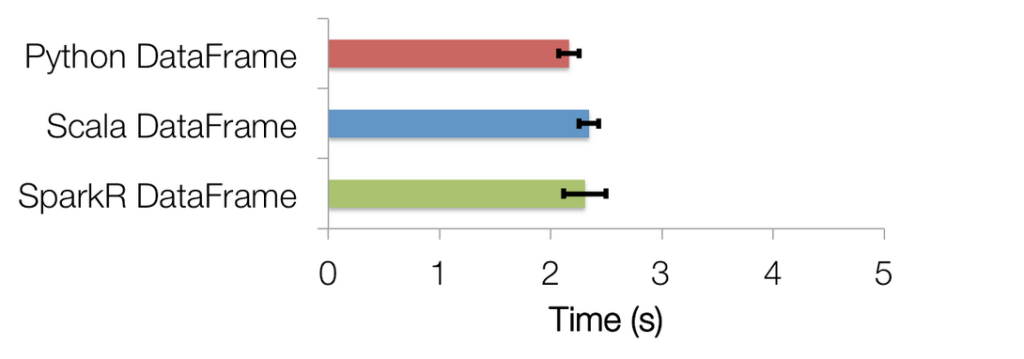
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 9年前 (2015-06-09) 36536℃ 1评论50喜欢
社区在Spark 1.3中开始引入了DataFrames,使得Apache Spark更加容易被使用。受R和Python中的data frames激发,Spark中的DataFrames提供了一些API,这些API在外部看起来像是操作单机的数据一样,而数据科学家对这些API非常地熟悉。统计是日常数据科学的一个重要组成部分。在即将发布的Spark 1.4中改进支持统计函数和数学函数(statistical and mathem w397090770 9年前 (2015-06-03) 13870℃ 2评论3喜欢
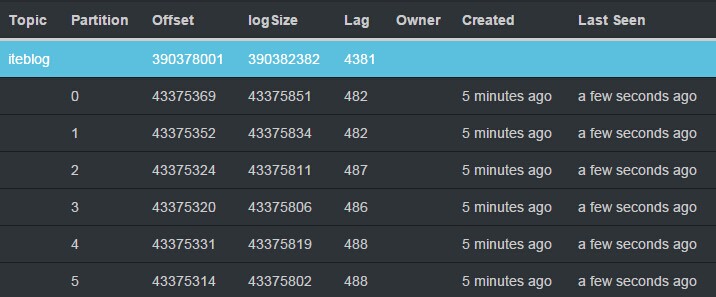
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护Kafka的读偏移量,而Spark Streaming系统并没有将这个消费的偏移量发送到Zookeeper中, w397090770 9年前 (2015-06-02) 25585℃ 36评论22喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符 w397090770 9年前 (2015-06-01) 60968℃ 2评论26喜欢
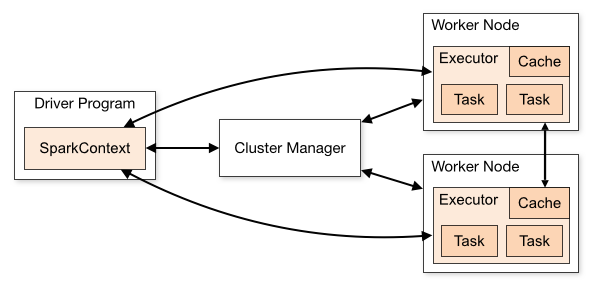
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基于1.3.0版本的Spark搭建了计算平台,实现基于Spark Streaming的实时 w397090770 9年前 (2015-05-30) 37306℃ 2评论76喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 9年前 (2015-05-29) 5381℃ 0评论3喜欢
MapReduce和Spark比较 目前的大数据处理可以分为以下三个类型: 1、复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间; 2、基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间; 3、基于实时数据流的数据处理(streaming data processing),通常的时间 w397090770 9年前 (2015-05-28) 4797℃ 0评论7喜欢