哎哟~404了~休息一下,下面的文章你可能很感兴趣:
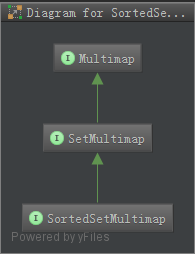
[caption id="attachment_756" align="aligncenter" width="195"] Gauva学习之SortedSetMultimap[/caption] SortedSetMultimap是一个接口,它的继承关系如上所示。继承了SortedSetMultimap接口的类中key所对应的value是有序的。因为SortedSetMultimap的子类中key所对应的value是有序的,所以SortedSetMultimap重写了SetMultimap中的以下四个方法:[code lang="JAVA"]@OverrideSortedSet< w397090770 11年前 (2013-09-27) 4045℃ 0评论3喜欢
本文主要讲解 Kafka 是什么、Kafka 的架构包括工作流程和存储机制,以及生产者和消费者,最终大家会掌握 Kafka 中最重要的概念,分别是 broker、producer、consumer、consumer group、topic、partition、replica、leader、follower,这是学会和理解 Kafka 的基础和必备内容。1. 定义Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主 w397090770 4年前 (2020-03-14) 1574℃ 0评论10喜欢
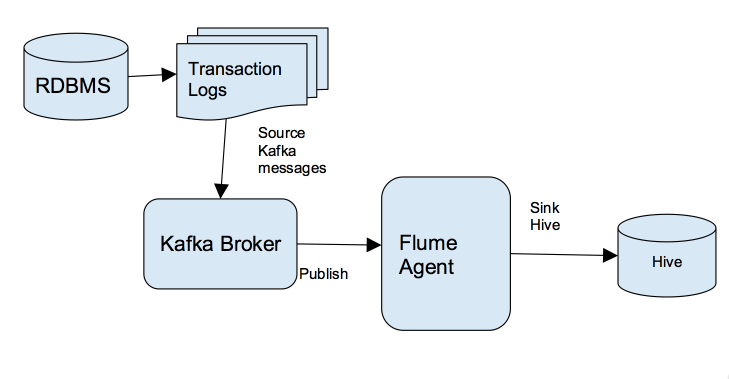
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 8年前 (2016-08-30) 11346℃ 6评论24喜欢
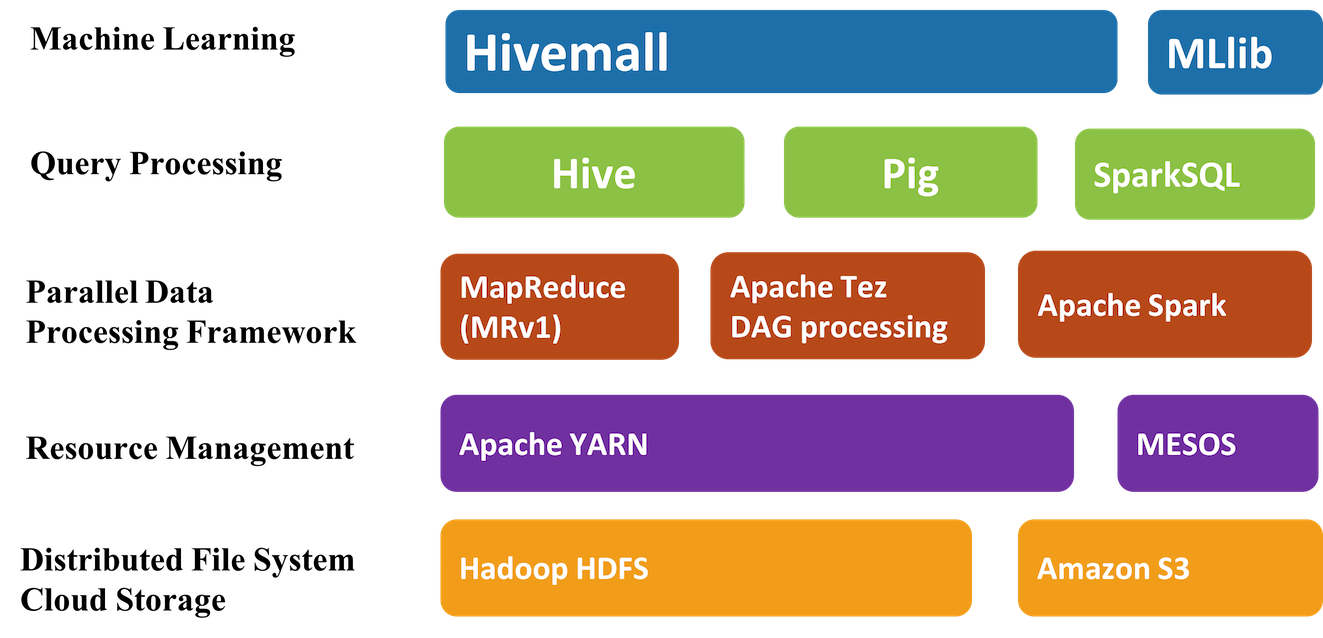
Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。 Apache Hivemall提供了各种功能包括:回归( w397090770 7年前 (2017-03-29) 3313℃ 1评论10喜欢
继续介绍如何在脚本中运行Scala,在前面的文章中我们只是简单地介绍了如何在脚本中使用Scala,本文将进一步地介绍。 在脚本中使用Scala最大的好处就是可以在脚本中使用Scala的所有高级特性,比如我们可以在脚本中定义和使用Scala class,如下:[code lang="scala"]#!/bin/shexec scala -savecompiled "$0" "$@"!#case c w397090770 8年前 (2015-12-15) 2626℃ 0评论5喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-15) 19316℃ 5评论10喜欢
我使用的是Spark 1.5.2和HDP 2.2.4.8,在启动spark-shell的时候出现了以下的异常:[code lang="bash"][itebog@www.iteblog.com ~]$ bin/spark-shell --master yarn-client...at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala):10: error: not found: value sqlContext import sqlContext.implicits._:10: error: not found: value sqlContext import sqlContext.sql[/code]你打开Application w397090770 8年前 (2016-01-15) 4600℃ 0评论2喜欢
Apache Flink 1.1.0于2016年08月08日正式发布,虽然发布了好多天了,我觉得还是有必要说说该版本的一些重大更新。Apache Flink 1.1.0是1.x.x系列版本的第一个主要版本,其API与1.0.0版本保持兼容。这就意味着你之前使用Flink 1.0.0稳定API编写的应用程序可以直接运行在Flink 1.1.0上面。本次发布共有95位贡献者参与,包括对Bug进行修复、新特 w397090770 8年前 (2016-08-18) 2062℃ 0评论0喜欢
1. 集群多少台, 数据量多大, 吞吐量是多大, 每天处理多少G的数据?2. 我们的日志是不是除了apache的访问日志是不是还有其他的日志?3. 假设我们有其他的日志是不是可以对这个日志有其他的业务分析?这些业务分析都有什么?4. 你们的服务器有多少台?服务器的内存多大?5. 你们的服务器怎么分布的?(这里说地理位置 w397090770 8年前 (2016-08-26) 3409℃ 0评论4喜欢
在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。数砖研发 Delta Engine 的目的过去十年,存储的速 w397090770 4年前 (2020-06-28) 989℃ 0评论1喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事在《Hive内置数据类型》文章中,我们提到了Hive w397090770 10年前 (2014-01-07) 139055℃ 1评论473喜欢
今天我将介绍如何在Java工程使用Scala代码。对于那些想在真实场景中尝试使用Scala的开发人员来说,会非常有意思。这和你项目中有什么类型的东西毫无关系:不管是Spring还是Spark还是别的。我们废话少说,开始吧。抽象Java Maven项工程 这里我们使用Maven来管理我们的Java项目,项目的结果如下所示:如果想及时了解Spa w397090770 7年前 (2017-01-01) 9815℃ 0评论24喜欢
c++中关于const的用法有很多,const既可以修饰变量,也可以函数,不同的环境下,是有不同的含义。今天来讲讲const加在函数前和函数后面的区别。比如:[code lang="CPP"]#include<iostream>using namespace std;// Ahthor: 过往记忆// E-mail: wyphao.2007@163.com// Blog: // 转载请注明出处class TestClass {public: size_t length() const; const char* ge w397090770 11年前 (2013-04-05) 24888℃ 1评论55喜欢
Short URL or tiny URL is an URL used to represent a long URL. For example, http://tinyurl.com/45lk7x will be redirect to http://www.snippetit.com/2008/10/implement-your-own-short-url.There are 2 main advantages of using short URL: Easy to remember - Instead of remember an URL with 50 or more characters, you only need to remember a few (5 or more depending on application's implementation). More portable - Some systems have limi w397090770 11年前 (2013-04-15) 20439℃ 0喜欢
上海Spark Meetup第五次聚会将于2015年7月18日在太库科技创业发展有限公司举办,详细地址上海市浦东新区金科路2889弄3号长泰广场 C座12层,太库。本次聚会由七牛和Intel联合举办。大会主题 1、hadoop/spark生态的落地实践 王团结(七牛)七牛云数据平台工程师。主要负责数据平台的设计研发工作。关注大数据处理,高 w397090770 9年前 (2015-07-06) 3144℃ 0评论6喜欢
Kafka 从首次发布之日起,已经走过了七个年头。从最开始的大规模消息系统,发展成为功能完善的分布式流式处理平台,用于发布和订阅、存储及实时地处理大规模流数据。来自世界各地的数千家公司在使用 Kafka,包括三分之一的 500 强公司。Kafka 以稳健的步伐向前迈进,首先加入了复制功能和无边界的键值数据存储,接着推出了用 w397090770 7年前 (2017-11-05) 24934℃ 0评论17喜欢
本文已经不再更新,谢谢支持。本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、Googl eusercontent、Gstatic、Google othe w397090770 4年前 (2019-11-19) 973℃ 0评论3喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 本文在上篇文章(《Kafka设计解析:Kafka High Availability(上)》)基础上,更加深入讲解了Kafka的HA机制,主要阐述了HA相关各种 w397090770 9年前 (2015-06-04) 4477℃ 0评论6喜欢
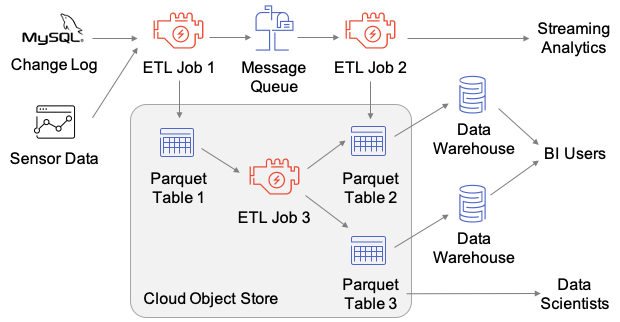
最近,数砖大佬们给 VLDB 投了一篇名为《Delta Lake: High-Performance ACID Table Storage overCloud Object Stores》的论文,并且被 VLDB 收录了,这是第一篇比较系统介绍数砖开发 Delta Lake 的论文。随着云对象存储(Cloud object stores)的普及,因为其廉价的成本,越来越多的企业都选择对象存储作为其海量数据的存储引擎。但是由于对象存储的特点 w397090770 4年前 (2020-08-25) 990℃ 0评论2喜欢
Spark GraphX in Action开头介绍了GraphX库可以干什么,并通过例子介绍了如何以交互的方式使用GraphX 。阅读完本书,您将学习到很多实用的技术,用于增强应用程序和将机器学习算法应用于图形数据中。 本书包括了以下几个知识点: (1)、Understanding graph technology (2)、Using the GraphX API (3)、Developing algorithms w397090770 7年前 (2017-02-12) 4679℃ 0评论5喜欢
Apache Kafka近年来迅速地成为开源社区流行的流输入平台。同时我们也看到了Spark Streaming的使用趋势和它类似。因此,在Spark 1.3中,社区对Kafka和Spark Streaming的整合做了很多重要的提升。主要修改如下: 1、为Kafka新增了新的Direct API。这个API可以使得每个Kafka记录仅且被处理一次(processed exactly once),即使读取过程中出现了失 w397090770 9年前 (2015-04-10) 16757℃ 0评论24喜欢
youtube-dl是一个精悍的命令程序,它可以从YouTube.com以及其他网站上下载视频。它是使用Python开发的,依赖于Python 2.6, 2.7, 或者3.2+解释器,而且这个视频下载命令是跨平台的,作者为我们带来了Windows执行文件(https://yt-dl.org/latest/youtube-dl.exe),其中就包含了Python。youtube-dl可以在Unix box,Windows或者是 Mac OS X平台上运行,支持众多视频网 w397090770 8年前 (2016-04-09) 6577℃ 0评论6喜欢
目前Spark支持四种方式从数据库中读取数据,这里以Mysql为例进行介绍。一、不指定查询条件 这个方式链接MySql的函数原型是:[code lang="scala"]def jdbc(url: String, table: String, properties: Properties): DataFrame[/code] 我们只需要提供Driver的url,需要查询的表名,以及连接表相关属性properties。下面是具体例子:[code lang="scala" w397090770 8年前 (2015-12-28) 37612℃ 1评论61喜欢
Apache Spark于北京时间2015年07月16日05点正式发布。Spark 1.4.1主要是维护版本,包含了大量的稳定性修复。该版本是基于branch-1.4分支。社区推荐所有1.4.0使用升级到这个稳定版本。此版本有85位开发者参与。 Spark 1.4.1包含了大量的Bug修复,这些Bug出现在Spark的DataFrame、外部数据源支持以及其他组建的一些bug修复。一些比较重要 w397090770 9年前 (2015-07-16) 4330℃ 0评论10喜欢
最近使用ElasticSearch的时候遇到以下的异常[code land="bash"]2017-07-27 16:06:48.482 MessageHandler - message process error: java.lang.NoClassDefFoundError: Could not initialize class org.elasticsearch.common.xcontent.smile.SmileXContent at org.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:124) ~[elasticsearch-2.3.4.jar:2.3.4] at org.elasticsearch.action.support.ToX w397090770 7年前 (2017-07-27) 8536℃ 0评论13喜欢
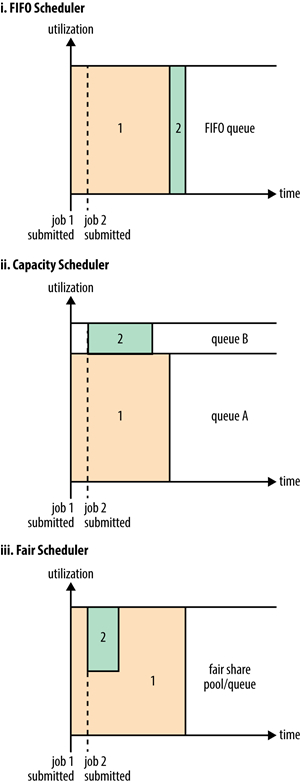
本文将介绍Hadoop YARN提供的三种任务调度策略:FIFO Scheduler,Capacity Scheduler 和 Fair Scheduler。FIFO Scheduler顾名思义,这就是先进先出(first in, first out)调度策略,所有的application将按照提交的顺序来执行,这些 application 都放在一个队列里,只有在执行完一个之后,才会继续执行下一个。这种调度策略很容易理解,但缺点也很明显 w397090770 9年前 (2015-11-29) 11469℃ 0评论30喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 第三次北京Spark Meetup活动将于2014年10月26日星期日的下午1:30到6:00在海淀区中关村科学院南路2号融科资讯中心A座8层举行,本次分享的主题主要是MLlib与分布式机器学 w397090770 10年前 (2014-10-09) 4443℃ 6评论5喜欢
我们已经在 这篇文章详细介绍了 Apache Spark Delta Lake 的事务日志是什么、主要用途以及如何工作的。那篇文章已经可以很好地给大家介绍 Delta Lake 的内部工作原理,原子性保证,本文为了学习的目的,带领大家从源码级别来看看 Delta Lake 事务日志的实现。在看本文时,强烈建议先看一下《深入理解 Apache Spark Delta Lake 的事务日志》文 w397090770 5年前 (2019-09-02) 1682℃ 0评论4喜欢
在高德纳的计算机程序设计艺术中,有如下问题:可否在一未知大小的集合中,随机取出一元素?。或者是Google面试题: I have a linked list of numbers of length N. N is very large and I don’t know in advance the exact value of N. How can I most efficiently write a function that will return k completely random numbers from the list(中文简化的意思就是:在不知道文件总行 w397090770 9年前 (2015-11-09) 10141℃ 0评论16喜欢
在本博客的《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(二)》两篇文章中我介绍了如何在Hadoop中根据Key或者Value的不同将属于不同的类型记录写到不同的文件中。在里面用到了MultipleOutputFormat这个类。 因为Spark内部写文件方式其实调用的都是Hadoop那一套东 w397090770 9年前 (2015-03-11) 20936℃ 19评论17喜欢












![[电子书]Spark GraphX in Action PDF下载](https://www.iteblog.com/pic/books/Spark_Graphx_in_Action_iteblog.png)