Hadoop YARN自带了一系列的web service REST API,我们可以通过这些web service访问集群(cluster)、节点(nodes)、应用(application)以及应用的历史信息。根据API返回的类型,这些URL源归会类到不同的组。一些API返回collector类型的,有些返回singleton类型。这些web service REST API的语法如下:[code lang="JAVA"]http://{http address of service}/ws/{version}/{resourcepa w397090770 10年前 (2014-02-27) 25955℃ 2评论18喜欢
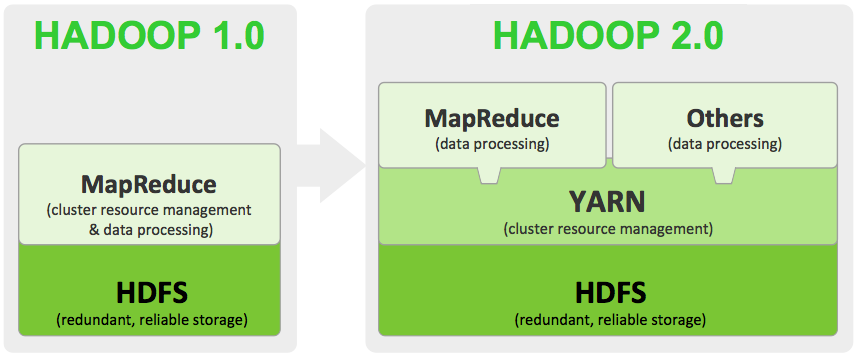
hadoop更新实在是太快了,现在已经更新到Hadoop-2.3.0版本(2014-02-11)。看了一下文档,和之前Hadoop-2.2.0的文档大部分类似,这篇文章主要是翻译一下Hadoop-2.3.0的文档。 Apache Hadoop 2.3.0和之前的Hadoop-1.x稳定版有了很大的提升。本篇文章主要是简要说说Hadoop 2.3.0中的HDFS和Mapreduce的提升(4、5两个特性是Hadoop2.x开始就支持的)。 w397090770 10年前 (2014-02-26) 7568℃ 2评论2喜欢
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器[code lang="JAVA"]$ sbin/mr-jobhistory-daemon.sh start historyserver w397090770 10年前 (2014-02-17) 29581℃ 8评论30喜欢
这是传智播客开办Hadoop培训以来的第一部视频教程,内容讲解精细,实战实例。是EasyHadoop创始人@童小军_HD 辛苦录制的Hadoop实战视频,视频一共包括14集,下载地址在下面。 本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44 w397090770 10年前 (2014-02-16) 172674℃ 7评论297喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》本博客收集到的Hadoop学习书籍分享地 w397090770 10年前 (2014-02-14) 202496℃ 5评论421喜欢
Hadoop自升级到2.x版本之后,有很多属性的名称已经被遗弃了,虽然这些被遗弃的属性名称目前还可以用,但是这里还是建议用新的属性名,主要遗弃的属性名称主要见下面表格:已经被遗弃属性的名称新的属性名称create.empty.dir.if.nonexistmapreduce.jobcontrol.createdir.ifnotexistdfs.access.time.precisiondfs.namenode.accesstime.prec w397090770 10年前 (2014-02-13) 17288℃ 0评论10喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 10年前 (2014-01-28) 7265℃ 2评论2喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 10年前 (2014-01-27) 5122℃ 1评论1喜欢
经过三个多月,发现自己已经写了好几篇关于常用Hadoop生态圈分布式安装的文章,比如Hadoop、Hive、Zookeeper、Hbase等软件的分布式安装,今天就汇总一下吧,这样也方便大家查阅,如果发现里面有任何错误可以邮件联系我(wyphao.2007@163.com)或者直接在相应文章里面留言,我会及时更正。 1、Hadoop-2.2.0伪分布式安装:《在Fedora w397090770 10年前 (2014-01-26) 6823℃ 1评论8喜欢
最近由于项目需要把Flume收集到的日志信息插入到Hbase中,由于第一次接触这些,在整合的过程中,我遇到了许多问题,我相信很多人也应该会遇到这些问题的,于是我把整个整合的过程写出来,希望给那些同样遇到这样问题的朋友帮助。 在使用Flume的时候,请确保你电脑里面已经搭建好Hadoop、Hbase、Zookeeper以及Flume。本文 w397090770 10年前 (2014-01-21) 11269℃ 6评论1喜欢



![传智播客Hadoop实战视频下载地址[共14集]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/4.jpg)
![传智播客Hadoop课程视频资料[共七天]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/9.jpg)
