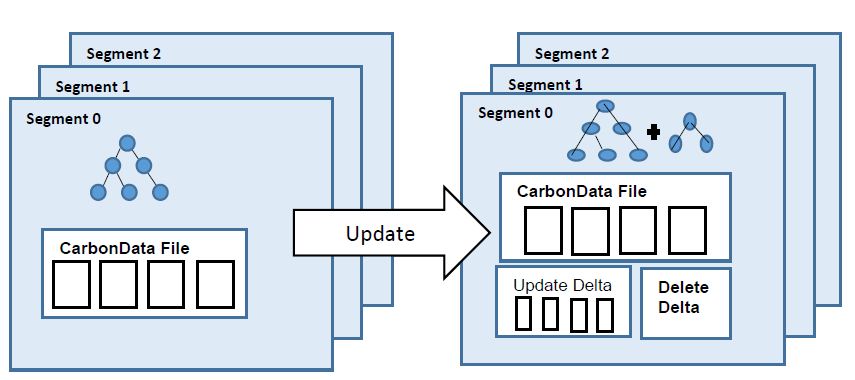
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。 当前,CarbonData暂不支持修改表中已经存在的数据。但是在现实情况下,我们可能很希望这个功能,比如修改 w397090770 7年前 (2016-11-30) 2775℃ 0评论10喜欢
本文相关测试数据由华为陈亮大神提供,特别感谢。 Apache CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询,目前该项目正处于Apache孵化过程中。详细介绍可以参见(《CarbonData:华为开发并支持Hadoop的 w397090770 8年前 (2016-09-11) 8133℃ 1评论7喜欢
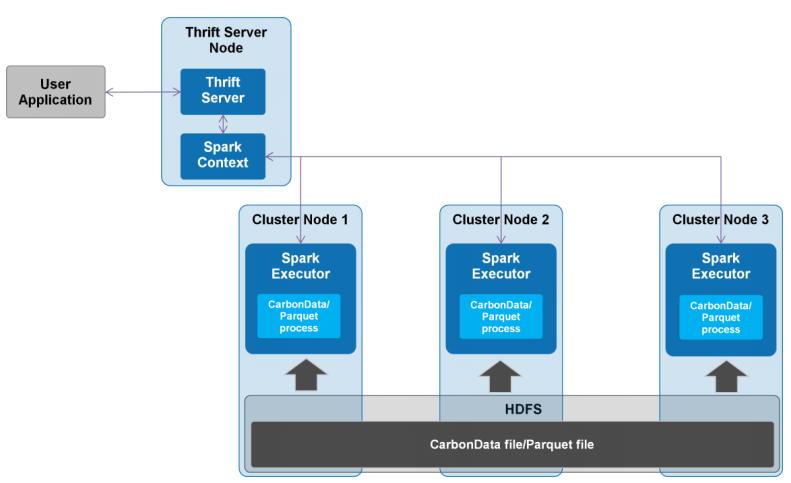
我们在《Apache CarbonData快速入门编程指南》文章中介绍了如何快速使用Apache CarbonData,为了简单起见,我们展示了如何在单机模式下使用Apache CarbonData。但是生产环境下一般都是使用集群模式,本文主要介绍如何在集群模式下使用Apache CarbonData。启动Spark shell这里以Spark shell模式进行介绍,master为yarn-client,启动Spark shell如下 w397090770 8年前 (2016-07-07) 2583℃ 1评论3喜欢
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。详情参见《CarbonData:华为开发并支持Hadoop的列式文件格式》,本文是单机模式下使用CarbonData的,如果你需要集群模 w397090770 8年前 (2016-07-01) 8319℃ 3评论6喜欢
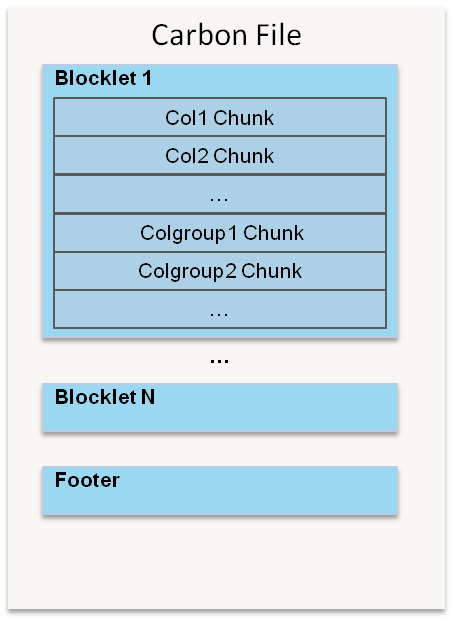
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 8年前 (2016-06-13) 5441℃ 0评论7喜欢