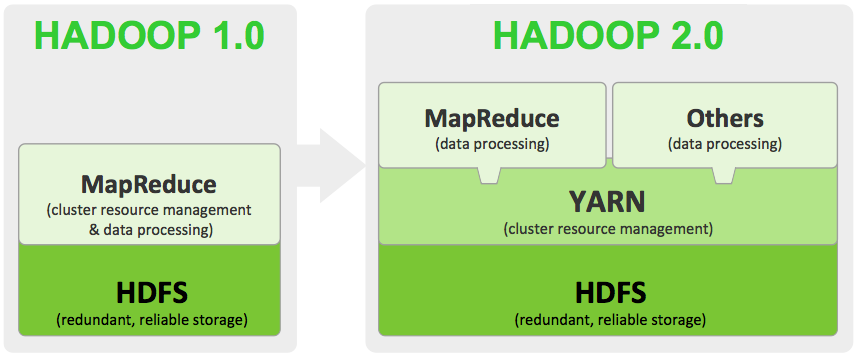
下面所有的内容是针对Hadoop 2.x版本进行说明的,Hadoop 1.x和这里有点不一样。 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:[code lang="JAVA"][wyp@wyp hadoop-2.2.0]$ $HADOOP_HOME/bin/hdfs namenode -format[/code] 格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构[code lang="JAVA"]c 10年前 (2014-03-04) 13238℃ 1评论17喜欢
Snappy是用C++开发的压缩和解压缩开发包,旨在提供高速压缩速度和合理的压缩率。Snappy比zlib更快,但文件相对要大20%到100%。在64位模式的Core i7处理器上,可达每秒250~500兆的压缩速度。 Snappy的前身是Zippy。虽然只是一个数据压缩库,它却被Google用于许多内部项目程,其中就包括BigTable,MapReduce和RPC。Google宣称它在这个库本 10年前 (2014-03-03) 13436℃ 1评论2喜欢
分布式计算开源框架Hadoop近日发布了今年的第一个版本Hadoop-2.3.0,新版本不仅增强了核心平台的大量功能,同时还修复了大量bug。新版本对HDFS做了两个非常重要的增强:(1)、支持异构的存储层次;(2)、通过数据节点为存储在HDFS中的数据提供了内存缓存功能。 借助于HDFS对异构存储层次的支持,我们将能够在同一个Hado 10年前 (2014-03-02) 4107℃ 0评论1喜欢
Hadoop YARN自带了一系列的web service REST API,我们可以通过这些web service访问集群(cluster)、节点(nodes)、应用(application)以及应用的历史信息。根据API返回的类型,这些URL源归会类到不同的组。一些API返回collector类型的,有些返回singleton类型。这些web service REST API的语法如下:[code lang="JAVA"]http://{http address of service}/ws/{version}/{resourcepa 10年前 (2014-02-27) 25961℃ 2评论18喜欢
hadoop更新实在是太快了,现在已经更新到Hadoop-2.3.0版本(2014-02-11)。看了一下文档,和之前Hadoop-2.2.0的文档大部分类似,这篇文章主要是翻译一下Hadoop-2.3.0的文档。 Apache Hadoop 2.3.0和之前的Hadoop-1.x稳定版有了很大的提升。本篇文章主要是简要说说Hadoop 2.3.0中的HDFS和Mapreduce的提升(4、5两个特性是Hadoop2.x开始就支持的)。 10年前 (2014-02-26) 7569℃ 2评论2喜欢
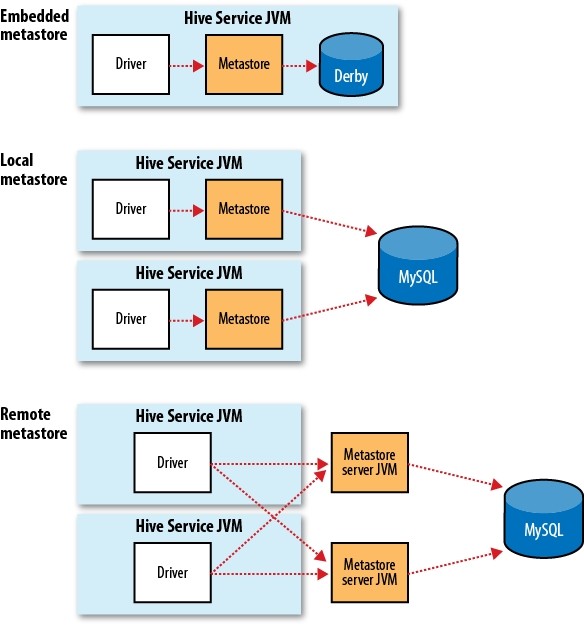
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 Hive内部自带了许多的服务,我们可以 10年前 (2014-02-24) 18892℃ 1评论10喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事在本博客的《Hive几种数据导入方式》文章 10年前 (2014-02-23) 76071℃ 5评论49喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 10年前 (2014-02-19) 92335℃ 5评论128喜欢
由于经常会使用到Flume的一些channel,source,sink,于是为了方便将这些channel,source,sink汇总出来,也共大家访问。Component InterfaceType AliasImplementation Class*.Channelmemory*.channel.MemoryChannel*.Channeljdbc*.channel.jdbc.JdbcChannel*.Channelfile*.channel.file.FileChannel*.Channel–*.channel.PseudoTxnMemoryChannel*.Channel–org.exa 10年前 (2014-02-19) 18900℃ 0评论13喜欢
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器[code lang="JAVA"]$ sbin/mr-jobhistory-daemon.sh start historyserver 10年前 (2014-02-17) 29585℃ 8评论30喜欢