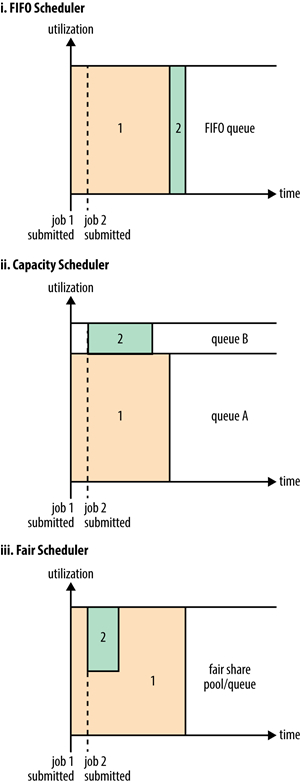
本文将介绍Hadoop YARN提供的三种任务调度策略:FIFO Scheduler,Capacity Scheduler 和 Fair Scheduler。FIFO Scheduler顾名思义,这就是先进先出(first in, first out)调度策略,所有的application将按照提交的顺序来执行,这些 application 都放在一个队列里,只有在执行完一个之后,才会继续执行下一个。这种调度策略很容易理解,但缺点也很明显 w397090770 9年前 (2015-11-29) 11473℃ 0评论30喜欢
显示分区[code lang="sql"]show partitions iteblog;[/code]添加分区[code lang="sql"]ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (partition_column = partition_col_value, partition_column = partition_col_value, ...)ALTER TABLE iteblog ADD PARTITION (dt='2008-08-08') location '/path/to/us/part080 w397090770 9年前 (2015-11-27) 9928℃ 0评论18喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次我对Spark RDD缓存的相关代码《Spark RDD缓存代码分析》进行了简要的介绍,本文将对Spark RDD的checkpint相关的代码进行相关的 w397090770 9年前 (2015-11-25) 8804℃ 5评论14喜欢
我们在使用Hive的时候经常会使用到order by、Sort by、Distribute by和Cluster By,本文对其含义进行介绍。order by Hive中的order by和数据库中的order by 功能一致,按照某一项或者几项排序输出,可以指定是升序或者是降序排序。它保证全局有序,但是进行order by的时候是将所有的数据全部发送到一个Reduce中,所以在大数据量的情 w397090770 9年前 (2015-11-19) 13980℃ 0评论16喜欢
今天将临时表里面的数据按照天分区插入到线上的表中去,出现了Hive创建的文件数大于100000个的情况,我的SQL如下:[code lang="sql"]///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2015-11-18 Time: 23:24 bolg: 本文地址:/archives/1533 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-11-18) 22750℃ 3评论53喜欢
我们知道,Spark相比Hadoop最大的一个优势就是可以将数据cache到内存,以供后面的计算使用。本文将对这部分的代码进行分析。 我们可以通过rdd.persist()或rdd.cache()来缓存RDD中的数据,cache()其实就是调用persist()实现的。persist()支持下面的几种存储级别:[code lang="scala"]val NONE = new StorageLevel(false, false, false, false)val DISK_ONLY = w397090770 9年前 (2015-11-17) 9592℃ 0评论15喜欢
Spark的作业会通过DAGScheduler的处理生产许多的Task并构建成DAG图,而分割出的Task最终是需要经过网络分发到不同的Executor。在分发的时候,Task一般都会依赖一些文件和Jar包,这些依赖的文件和Jar会对增加分发的时间,所以Spark在分发Task的时候会将Task进行序列化,包括对依赖文件和Jar包的序列化。这个是通过spark.closure.serializer参数 w397090770 9年前 (2015-11-16) 6184℃ 0评论8喜欢
最近由Reynold Xin给Spark开发者发布的一封邮件透露,Spark社区很有可能会跳过Spark 1.7版本的发布,而直接转向Spark 2.x。 如果Spark 2.x发布,那么它将: (1)、Spark编译将默认使用Scala 2.11,但是还是会支持Scala 2.10。 (2)、移除对Hadoop 1.x的支持。不过也有可能移除对Hadoop 2.2以下版本的支持,因为Hadoop 2.0和2.1版本分 w397090770 9年前 (2015-11-13) 6961℃ 0评论16喜欢
Hive 1.2.1源码编译依赖的Hadoop版本必须最少是2.6.0,因为里面用到了Hadoop的org.apache.hadoop.crypto.key.KeyProvider和org.apache.hadoop.crypto.key.KeyProviderFactory两个类,而这两个类在Hadoop 2.6.0才出现,否者会出现以下编译错误:[ERROR] /home/q/spark/apache-hive-1.2.1-src/shims/0.23/src/main/java/org/apache/hadoop/hive/shims/Hadoop23Shims.java:[43,36] package org.apache.hadoop.cry w397090770 9年前 (2015-11-11) 13438℃ 11评论6喜欢
在Spark中分区器直接决定了RDD中分区的个数;也决定了RDD中每条数据经过Shuffle过程属于哪个分区;也决定了Reduce的个数。这三点看起来是不同的方面的,但其深层的含义是一致的。 我们需要注意的是,只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None的。 在Spark中,存在两类分区函数:HashPartitioner w397090770 9年前 (2015-11-10) 18335℃ 2评论40喜欢