

CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。
为什么重新设计一种文件格式
目前华为针对数据的需求分析主要有以下5点要求:
1、支持海量数据扫描并取其中几列;
2、支持根据主键进行查找,并在压秒级响应;
3、支持在海量数据进行类似于OLAP的交互式查询,并且查询中涉及到许多过滤条件,这种类型的workload应该在几秒钟内响应;
4、支持快速地抽取单独的记录,并且从该记录中获取到所有列信息;
5、支持HDFS,这样客户可以利用现有的Hadoop集群。
目前现有的Hadoop生态系统中没有同时满足这五点要求文件格式。比如Parquet/ORC的文件仅仅满足第一和第五条要求,而其他的要求无法满足,所以基于这些事实华为开始开发CarbonData。
CarbonData有啥优势
CarbonData文件格式是基于列式存储的,并存储在HDFS之上;其包含了现有列式存储文件格式的许多有点,比如:可分割、可压缩、支持复杂数据类型等;并且CarbonData为了解决上面5点要求,加入了许多独特的特性,主要概括为以下四点:
1、存储数据及其索引:在有过滤的查询中,它可以显著地加速查询性能,减少I/O和CPU资源。CarbonData的索引由多级索引组成,处理框架可以利用这些索引信息来减少调度和一些处理的开销;在任务扫描数据的时候它可以仅仅扫描更细粒度的单元(称为blocklet),而不需要扫描整个文件。
2、可操作的编码数据:通过支持高效的压缩和全局编码模式,它可以直接在压缩或者编码的数据上查询,仅仅在需要返回结果的时候才进行转换,这种技术被称为late materialized。
3、列组:支持多列组成一个列组,并且使用行格式进行存储,这减少了查询时行重建的开销。
4、支持多种使用场景:比如支持类OLAP风格的交互式查询、顺序存取、随机访问等。
CarbonData文件格式
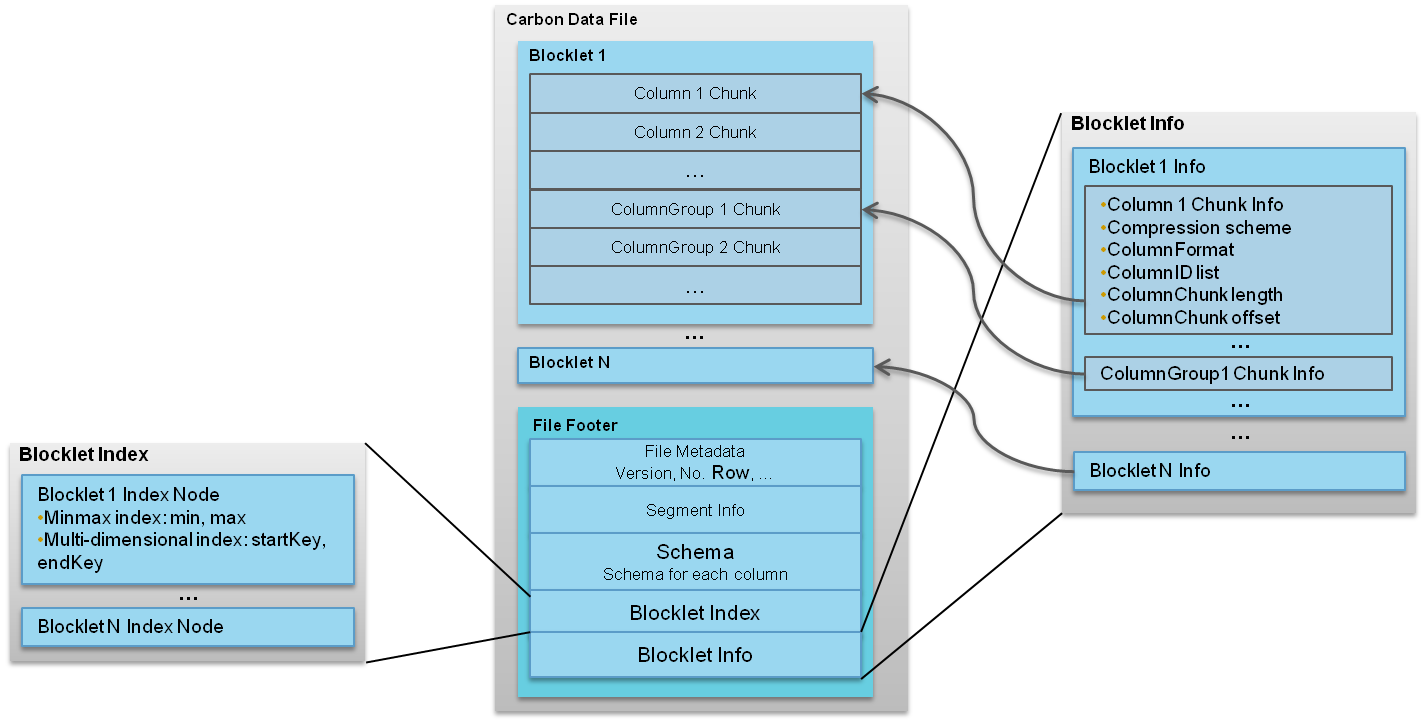
一个CarbonData文件是由一系列被称为blocklet组成的;除了blocklet,还有许多其他的元信息,比如模式、偏移量以及索引信息等,这些元信息是存储在CarbonData文件中的footer里。
每当在内存中建立索引的时候都需要读取footer里面的信息,因为可以利用这些信息优化后续所有的查询。
每个blocklet又是由许多Data Chunks组成。Data Chunks里面的数据既可以按列或者行的形式存储;数据既可以是单独的一列也可以是许多列。文件中所有的blocklets都包含相同数量和类型的Data Chunks。CarbonData文件格式如下所示:
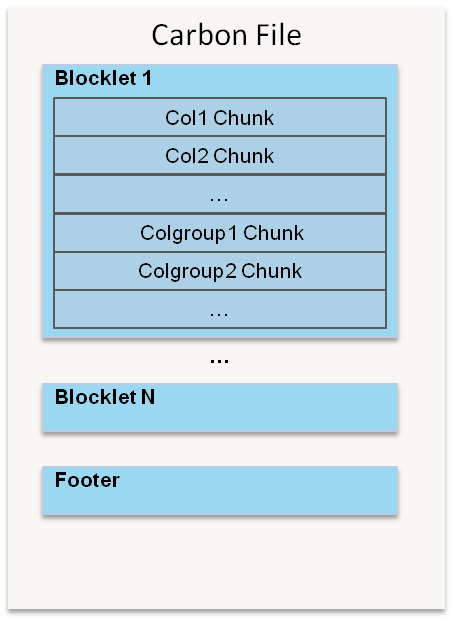
每个Data Chunk又是由许多被称为Pages的单元组成。总共有三种类型的pages:
1、Data Page:包含一列或者列组的编码数据;
2、Row ID Page:包含行id的映射,在Data Page以反向索引的形式存储时会被使用;
3、RLE Page:包含一些额外的元信息,只有在Data Page使用RLE编码的时候会被使用。
CarbonData文件的详细信息如下:
编译CarbonData
编译CarbonData的预备条件:
1、类Unix环境(Linux, Mac OS X)
2、git
3、Apache Maven (推荐使用3.0.4)
4、Java 7 or 8
5、Scala 2.10
6、Apache Thrift 0.9.3
从github中克隆CarbonData
$ git clone https://github.com/HuaweiBigData/carbondata.git
根据自己需求依次选择下面命令编译CarbonData
1、Build without testing
$ cd carbondata $ mvn -DskipTests clean install
2、Build with testing:
$ cd carbondata $ mvn clean install
3、Build along with integration test cases
$ cd carbondata $ mvn -Pintegration-test clean install
更多关于Carbondata的信息请参见https://github.com/HuaweiBigData/carbondata
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【CarbonData:华为开发并支持Hadoop的列式文件格式】(https://www.iteblog.com/archives/1689.html)







